글을 시작하기에 앞서 해당 시리즈는 Allen Downey, Ben Lauwens의 저서인 Think Julia: How to Think Like a Computer Scientist 를 바탕으로 작성된 글임을 알려드립니다.
이 포스트는 Subtyping를 한글로 요약 정리한 글입니다.
서브타이핑 (Subtyping)
이전 장에서는 다중 디스패치 매커니즘과 폴리모픽 메서드에 대해서 알아보았다. 인수 데이터 타입을 지정하지 않으면 모든 데이터 타입이 인수로 사용가능한 메서드가 생성된다. 메서드에서 허용된 데이터 타입의 서브셋(subset)을 지정하는 것은 다음 단계이다.
이번 장에서는 카드 놀이에서의 카드 덱 및 포커 패를 나타내는 데이터 타입을 사용한 서브타이핑을 볼 것이다. 만약 포커를 해본 적이 없다면, 해당 링크에서 관련 정보를 읽을 수 있다.
카드
덱에 4개의 모양과 13개의 순위로 조합된 52개의 카드가 있다. 모양은 하트(♥), 스페이드(♠), 다이아몬드(♦), 클로버(♣)으로 구성되어 있다. 순위는 에이스(A), 2, 3, 4, 5, 6, 7, 8, 9, 10, 잭(J), 퀸(Q), 킹(K)으로 나눠져있다. 게임을 진행할 때는 에이스가 킹보다 높으며 2보다는 낮다.
카드를 표현하기 위해 새로운 객체를 정의한다면, 객체는 무슨 속성을 가져야 하는지가 명확하다. 바로 모양과 순위이다. 하지만 이 사실이 어떤 데이터 타입의 속성이어야 하는지와 연결되지는 않는다. 한 가지 방안은 "Spade"와 "Queen"처럼 문자열을 사용하는 것이다. 이런 구현의 문제점은 카드들의 순위와 모양을 비교하는 것이 어렵다는 점이다.
대안으로는 모양과 순위를 인코드(encode)하기 위해 정수를 사용하는 것이다. 인코드(encode)란 숫자와 모양 또는 숫자와 순위 사이에 매핑을 정의하는 것을 의미한다. 이런 종류의 인코딩은 암호화(encryption)이다.
예를 들어 아래의 정보는 각 모양과 이에 연결되는 정수 코드를 보여준다.
♠-> 4♥-> 3♦-> 2♣-> 1
이 코드는 높은 값의 모양은 높은 숫자에 매핑했기 때문에 카드들을 비교하기가 더 쉽다. 우리는 카드들의 정수 코드를 사용하여 비교할 수 있다.
위에서 사용한 -> 기호는 줄리아 프로그램에서 사용하는 것은 아니지만 매핑을 명확히 보여주기 위해서 사용한 것이다. 이와 같은 기호들은 프로그램 디자인의 일부이며, 코드에는 나타나지 않는다.
Card 구조체의 정의는 아래와 같다.
1 | struct Card |
Card를 만들기 위해서는 Card()에 원하는 모양과 순위를 넣어 호출해야 한다.
1 | julia> queen_of_diamonds = Card(2, 12) |
글로벌 변수 (Global Variables)
사람들이 쉽게 읽을 수 있도록 하는 Card 객체를 출력하기 위해서는 정수 코드로 매핑된 모양과 순위가 필요하다. 보편적인 방법은 문자열 배열로 만드는 것이다.
1 | const suit_names = ["♣", "♦", "♥", "♠"] |
suit_names과 rank_names은 글로벌 변수이다. const 선언은 변수가 오직 하나에만 할당되도록 한다. 이것은 글로벌 변수들의 실행 문제들을 해결해준다.
이제 우리는 적절한 show 메서드를 구현할 수 있다.
1 | function Base.show(io::IO, card::Card) |
rank_names[card.rank] 표현식은 “rank_names 배열의 인덱스로 Card 객체의 rank필드를 사용하라 그리고 알맞은 인수를 선택하라” 를 표현한 것이다.
지금까지 완성한 메서드를 사용하면, 우리는 출력된 카드를 얻을 수 있다.
1 | julia> Card(3, 11) |
카드 비교하기 (Comparing Cards)
내장 데이터 타입에서는 관계 연산자(<, >, ==, etc.)가 값들을 비교하여 큰지, 작은지 또는 같은지를 결정한다. 하지만 개발자가 정의한 고유 데이터 타입에서는 < 메서드를 제공하여 내장 연산자들의 실행을 가져올 수 있다.
카드를 정확하게 순서대로 나열하는 것은 명확하지 않다. 예를 들어 3 클로버와 2 다이아몬드 중에 무엇이 더 나은가? 하나는 보다 높은 순위지만 낮은 모양이고, 다른 것은 낮은 순위지만 높은 모양이다. 카드들을 비교하기 위해서는 순위와 모양 중 무엇이 더 중요한지를 결정해야 한다.
답은 아마 게임을 어떤 게임을 하고 있는지에 따라서 나뉘겠지만, 간단하게 하기 위해서 우리는 모양이 더 중요하다고 임의로 선택할 것이다. 따라서 모든 스페이드는 모든 다이아몬드보다 더 중요하다.
해당 사항을 <로 작성할 수 있다.
1 | import Base.< |
유닛 테스팅 (Unit Testing)
유닛 테스팅은 코드가 예상했던 대로 정확하게 작동하는지 확인해준다. 이 방법은 코드 수정 후에도 제대로 작동하는지 확인하기 위해서 사용하며, 또한 개발 중에도 코드 실행이 잘 작동하는지 미리 정의해볼 수 있다.
간단한 유닛 테스팅은 @test메크로로 실행된다.
1 | julia> using Test |
만약 따라오는 표현식이 true라면 @test는 "Test Passed"를 반환하고 false라면 "Test Failed"를 반환한다 그리고 표현식이 아예 평가될 수 없다면 "error result"를 반환한다.
덱 (Decks)
지금까지는 카드를 만들었으며, 다음 단계로는 덱을 정의하는 것이다. 덱은 카드로 만들어졌기 때문에 각각의 덱은 카드 배열을 속성으로서 포함하는 것이 당연하다.
아래는 Deck 구조체 정의이다. 생성자는 필드로 cards를 가지며, 52개 카드의 기본 세트를 일반화한다.
1 | struct Deck |
덱을 채우는 가장 쉬운 방법은 ‘중첩 루프(nested loop)’를 사용하는 것이다. 바깥의 루프는 1부터 4까지의 모양을 열거하며, 내부의 루프는 1부터 13의 순위를 열거한다. 각 반복은 최신의 모양과 순위를 포함한 새로운 Card를 생성하여 deck.cards에 밀어넣는다.
아래는 Deck을 보여주는 show메서드이다.
1 | function Base.show(io::IO, deck::Deck) |
결과는 아래와 같다.
1 | julia> Deck() |
추가, 제거, 셔플 그리고 정렬
카드를 다루려면 덱으로부터 카드를 제거하고 반환하는 함수가 필요하다. pop!()은 편리하게 이를 수행할 수 있다.
1 | function Base.pop!(deck::Deck) |
pop!()은 배열에서 마지막 카드를 제거하기 때문에
카드를 추가하기 위해서는 push!()를 사용하면 된다.
1 | function Base.push!(deck::Deck, card::Card) |
한번에 많은 작업들을 수행하지 않고 다른 메서드를 사용하는 방식을 ‘비니어(veneer)’라고도 부른다. 비니어는 원래 목공에서 사용되는 단어이며, 고급스럽게 보이기 위해 싼 목재 표면에 비싼 목재를 붙일 때 사용되는 고품질의 얇은 층을 의미한다.
이 예시에서 push!는 덱에 알맞는 배열 작동을 표현하는 얇은 메서드이며, 이 방식은 구현의 인터페이스나 외관을 향상시킨다.
또 다른 예시로서, Random을 사용하여 suffle!()이라는 함수를 작성해보자.
1 | using Random |
추상 데이터 타입과 서브타이핑
우리는 카드를 들고 있는 ‘손’을 표현하는 데이터 타입을 원한다. 손과 덱은 카드 모음을 만들고 추가 및 제거 작동이 필요하다는 점에서 비슷하다. 하지만 손과 덱은 다른 점도 분명히 있다. 예를 들어 포커에서는 두 손을 비교하여 누가 이길지를 비교해야 하고, 각 손의 점수를 계산해야 한다.
그래서 구체적인 데이터 타입을 그룹화하는 방법이 필요하다. 줄리아에서는 덱과 손의 부모처럼 제공하는 ‘추상 데이터 타입(abstract type)’을 정의하여 제공한다. 이를 ‘서브타이핑(subtyping)’이라고 한다.
추상 데이터 타입인 CardSet을 불러오자.
1 | abstract type CardSet end |
새로운 추상 데이터 타입은 abstract type으로 생성된다. 선택적인 “부모” 데이터 타입도 존재하는 추상 데이터 타입을 <: 뒤에 작성함으로써 구체회될 수 있다.
supretype이 주어지지 않으면, 기본 supretype은 Any로 지정된다. Any는 모든 객체가 인스턴스이고 모든 데이터 타입이 서브타입인 추상 데이터 타입이다.
지금부터는 CardSet의 자식인 Deck읖 나타낼 수 있다.
1 | struct Deck <: CardSet |
isa연산자는 해당 객체가 주어진 데이터 타입이 맞는지 확인해준다.
1 | julia> deck = Deck(); |
또한 손도 CardSet의 종류 중 하나이다.
1 | struct Hand <: CardSet |
52개의 새로운 카드를 손에 채우는 대신, Hand 생성자는 cards를 빈 배열과 함께 초기화한다. 선택적 인수는 생성자에 전달되어 Hand에 라벨을 제공한다.
1 | julia> hand = Hand("new hand") |
추상 데이터 타입과 함수
이제부터는 CardSet을 인수로 가진 함수를 통해 Deck과 Hand 사이의 공통 작업을 표현할 수 있다.
1 | function Base.show(io::IO, cs::CardSet) |
카드를 다루기 위해 pop!()과 push!()를 사용할 수 있다.
1 | julia> deck = Deck() |
자연스러운 다음 단계는 move!()에서 해당 코드를 캡슐화하는 것이다.
1 | function move!(cs1::CardSet, cs2::CardSet, n::Int) |
move!()는 두 개의 CardSet 객체와 카드를 처리할 수까지 총 세 개의 인수를 가져간다. 두 개의 CardSet 객체는 변경가능하며, nothing을 반환한다.
게임에서 카드들은 한 손에서 다른 손으로 가거나 손에서 덱으로 이동한다. 이런 작동들은 모두 move!()를 사용하면 된다. 즉, cs1과 cs2는 Deck이나 hand일 수 있다.
데이터 타입 다이어그램
지금까지는 프로그램의 상태를 보여주는 스택 다이어그램과 객체와 값의 속성을 보여주는 객체 다이어그램을 살펴보았다. 이런 다이어그램들은 프로그램 실행에서 스냅샷을 나타내므로 프로그램이 실행되면 이들도 변한다.
또한 다이어그램은 가끔 과도하게 상세하다. ‘데이터 타입 다이어그램(type diagram)’은 프로그램 구조를 더 추상적으로 표현한다. 개별적인 객체를 모두 보여주는 것 대신에 데이터 타입의 관계만을 보여준다.
데이터 타입 사이의 관계의 종류는 여러 가지이다.
구체적인 데이터 타입의 객체는 다른 데이터 타입의 객체로부터 참조를 포함할 수 있다. 에를 들어, 각 직사각형은 Point의 참조를 포함하고, 덱은 카드 배열의 참조를 포함한다. 이런 관계의 종류는 “HAS-A”라고 한다. 즉, “직사각형은 포인트를 참조한다 (a Rectangle has a Point)” 인 것이다.
구체적인 데이터 타입은 서브데이터 타입으로서 추상 데이터 타입을 가진다. 이런 관계의 종류를 “IS-A”이다. 즉, “손은 Cardset의 종류이다.(a Hand is a kind of a CardSet)” 이다.
한 데이터 타입의 객체는 다른 데이터 타입의 객체를 매개 변수로 사용하거나 계산의 일부로 사용한다는 점에서 다른 데이터 타입에 따라 달라질 수 있다. 이런 관계를 “종속성(dependency)”이라고 한다.
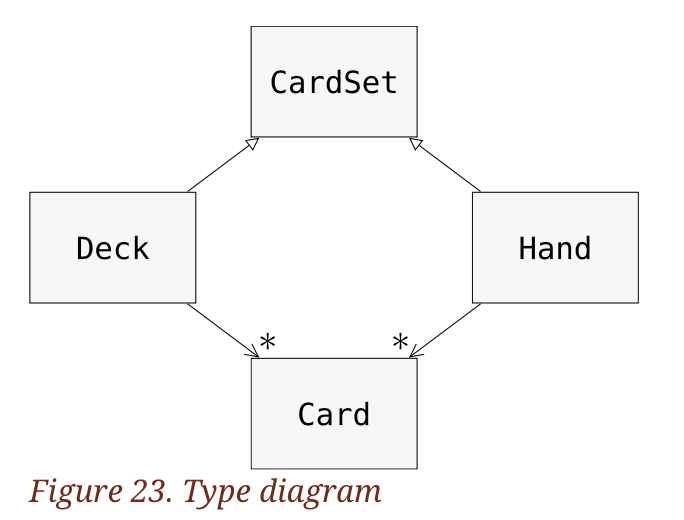
위의 다이어그램에서 속인 빈 화살표는 IS-A 관계를 보여준다. Hand는 CardSet의 서브데이터 타입을 가지고 있다.
일반적인 화살표는 HAS-A 관계를 보여준다. Deck은 Card객체를 참조한다.
옆에 *를 가진 화살표는 다수(multiplicity)이다. 이것은 Deck이 얼마나 많은 카드를 가지고 있는지를 표시한다. 다수(multiplicity)는 52와 같은 간단한 숫자나 like 5:7같은 범위, Deck이 여러 개의 Cards를 가진다는 별 표시 등으로 표현된다.
종속성은 위의 다이어그램에 없다. 일반적으로 종속성은 점선 화살표로 표시되며, 종속성이 많을 때에는 생략되기도 한다.
다이어그램의 세부사항들은 Deck이 카드들의 배열을 포함한다는 것을 보여주지만, 배열이나 딕셔너리같은 내장 데이터 타입들은 보통 타입 다이어그램에 포함되지 않는다.
디버깅
서브타이핑은 객체를 인수로 가진 함수를 호출할 때 어떤 메서드가 호출되는지 파악하기 힘드므로 디버깅하기 어렵게 만든다.
Hand객체에서 작동하는 함수를 작성한다고 가정해보자. 그러면 +PokerHand+s, +BridgeHand+s와 같은 hand+s의 모든 종류들에 작동할 수 있도록 만들고 싶을 것이다. +sort!와 같은 메서드를 호출하면 추상 데이터 타입인 Hand에 대해 정의된 메서드를 얻을 수 있다. 하지만 서브데이터 타입 중 하나를 인수로 사용하는 sort!메서드가 존재한다면, 아레의 버전을 얻게 될 것이다. 이런 방식은 보통 좋지만, 때로는 헷갈릴 수 있다.
1 | function Base.sort!(hand::Hand) |
프로그램을 통한 실행 흐름에 대해 확실할 수 없는 경우 가장 간단한 해결책은 관련 메서드 시작부분에 print문을 추가하는 것이다. shuffle!이 Running shuffle! Deck과 같은 메시지를 출력하면, 프로그램이 작동할 때 실행 흐름을 추적한다.
더 나은 대안으로는 @which 매크로를 사용하는 것이다.
1 | julia> sort!(hand) |
그러면 Hand의 sort! 메서드는 인수로서 Hand 데이터 타입의 객체 하나를 가진다.
설계 제안은 다음과 같다.
메서드를 재정의(override)할 때, 새로운 메서드의 인터페이스는 이전 메서드와 동일해야 한다. 동일한 매개 변수를 가져가고 동일한 데이터 타입을 반환하며 동이란 전제 조건 및 사후 조건을 준수해야 한다. 이 조건을 따른다면, CardSet과 같은 supertype의 인스턴스와 같이 작동하도록 설계된 함수가 서브데이터 타입인 Deck과 Hand의 인스턴스에도 작동한다는 것을 알 수 있다.
이와 같은 ‘리스코프 치환 규칙(Liskov substitution principle)’을 어긴다면, 해당 코드는 아마 붕괴할 것이다.
supertype()은 데이터 타입의 supertype을 찾아준다.
1 | julia> supertype(Deck) |
데이터 캡슐화
이전 섹션에서는 ‘데이터 타입 지향 디자인 (type-oriented design)’이라는 개발 계획을 보여줬다. 우리는 Point,Rectangle,MyTime과 같이 필요한 객체들을 확인하고, 그들을 표현하기 위해 구조체를 정의하였다. 각각의 경우에는 객체와 현실세계의 실체 사이에 명백한 대응 관계가 있다.
그러나 때로는 어떤 객체가 필요한지, 어떻게 상호작용해야 하는지 명확하지 않다. 이 경우에는 다른 개발 계획이 필요하다. 캡슐화와 일반화를 통해 함수 인터페이스로 발견한 것과 같은 방식으로 우리는 데이터 캡슐화를 통해 데이터 타입 인터페이스를 발견할 수 있다.
12장에서 본 마르코프 분석이 좋은 예시이다. 아래의 코드는 글로벌 변수인 prefix와 suffixes를 정의한 것이다. 이 변수들은 여러 함수에서 사용될 것이다.
1 | suffixes = Dict() |
위의 변수들은 글로벌 변수이기 때문에 한 번에 하나의 분석만 실행할 수 있다. 두 개의 텍스트를 읽으면 접두사와 접미사가 동일한 데이터 구조에 추가되어 흥미로운 생성 텍스트가 만들어진다.
여러 분석을 실행하고, 별도로 유지하기 위해서는 각 분석의 상태를 객체에 캡슐화할 수 있다. 아래의 코드를 통해 확인하자.
1 | struct Markov |
그 다음, 함수를 메서드를 변환한다. 예를 들어 아래의 processword를 보자.
1 | function processword(markov::Markov, word::String) |
작동을 변경하지 않고 디자인만 변경하는 프로그램 변환은 리팩토링의 또 다른 예시이다.
이 예시는 데이터 타입 설계를 위한 개발 계획을 제시한다.
글로벌 변수를 읽고 쓰는 함수를 시작하시오.
프로그램이 작동하면 전역 변수들과 그들을 사용하는 함수 사이의 연관성을 찾으시오.
관련 변수를 구조체의 필드로서 캡슐화하시오.
연관된 함수들을 새로운 데이터 타입의 객체가 인수인 메서드로 변환하시오.