터미널에서 코드만을 사용하여 AWS S3 버킷에 접속하는 방법을 정리합니다.
AWS S3
S3(Simple Storage Service)는 AWS에서 제공하는 데이터 저장소이다. S3는 웹 기반으로 이루어져 있기 때문에 정적 휍 호스팅을 직접 관리할 수 있으며, 가상 서버인 EC2와도 데이터를 주고 받을 수 있다. 또한 데이터 저장량을 미리 결정해야 하는 EBS와 달리 S3는 무제한으로 데이터를 저장할 수 있다. 경제적인 이점을 제외하고서도 이런 장점들로 인해서 S3는 많이 사용된다.
객체 (object)
객체는 S3에 데이터가 저장되는 기본 단위이다. 객체 종류로는 파일과 메타데이터가 있다. 일반적인 파일은 1개당 1Byte부터 5TB 까지 저장 가능하며, 메타데이터는 MIME 형식으로 파일 확장자를 자동으로 변경하여 저장된다. 메타데이터의 확장자는 사용자가 임의로 설정할 수도 있다.
버킷 (bucket)
버킷 (bucket)은 S3에서 데이터를 저장하는 최상위 저장소이다. 모든 데이터들은 버킷 안에 저장할 수 있으며, 버킷 없이 데이터를 업로드하는 것은 불가능하다. 각 AWS 계정별로 100개까지 생성할 수 있으며, 각 버킷에는 무제한으로 객체들을 저장할 수 있다.
boto3 library
boto3는 파이썬에서 S3를 사용할 수 있도록 해주는 라이브러리이다. 아직 다운받지 않았다면 아래의 코드를 입력하면 된다.
1 | > pip3 install boto3 |
다운이 완료되었다면 그 다음으로는 파이썬에 접속한 후 아래의 코드를 입력하여 해당 라이브러리를 가져온다.
1 | > import boto3 |
버킷 생성하기
커맨드라인에서 S3를 사용할 준비가 완료되었다. 이제부터는 훈련 데이터를 넣을 버킷을 생성해보자. 아래의 코드를 입력하여 S3에 접속한다.
1 | > s3 = boto3.client('s3') |
그 다음 버킷 이름을 설정하고, 버킷을 생성한다. 아래의 코드는 서울을 지역으로 설정하여 설정한 이름의 버킷을 생성한다.
1 | > bucket_name = '원하는 이름' |
Warining
버킷의 이름은 전세계적으로 단 하나의 이름이어야 한다. 따라서 만약 누군가 사용하고 있는 이름을 입력하면 아래와 같은 오류가 발생하고, 버킷이 생성되지 않는다.
1 | Traceback (most recent call last): |
버킷 이름을 만들 때 주의해야 할 요소는 아래와 같다.
버킷 이름은 3~63자로 이루어져야 하며 소문자와 숫자, 마침표 및 대시만 포함할 수 있다.
버킷 이름은 소문자 또는 숫자로 시작해야 한다.
버킷 이름은 밑줄을 포함하거나, 대시로 끝나거나, 마침표가 있거나, 마침표와 인접해 대시를 사용할 수 없다.
버킷 이름에 IP 주소 형식(198.51.100.24)을 사용할 수 없다.
이제 버킷 생성이 잘 되었는지 확인해보자. 아래의 코드를 입력하면 해당 계정의 버킷들의 목록을 볼 수 있다.
1 | > s3.list_buckets() |
또한 AWS 사이트에 직접 로그인하여 S3를 확인해봐도 버킷이 생성되었음을 확인할 수 있다.
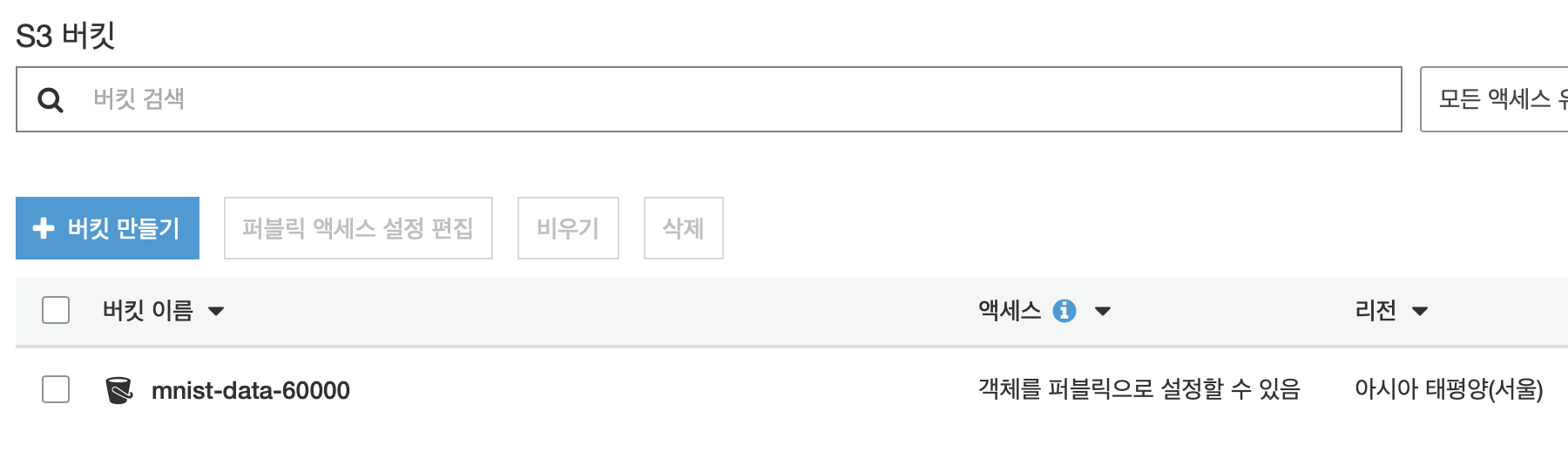
버킷에 훈련 데이터 업로드하기
해당 프로젝트에서는 간단하게 손글씨 데이터인 MNIST를 사용할 예정이다. 깃허브에 가면 MNIST 데이터를 바로 다운받을 수 있다. 데이터 압축을 풀면 확장자 plckle인 MNIST 데이터 파일이 4개가 있을 것이다. 데이터 정보는 다음과 같다.
- train_x.pickle : 훈련 이미지 데이터 (shape: 60000 x 28 x 28 x 1)
- train_y.pickle : 훈련 정답 데이터 (shape: 60000)
- test_x.pickle : 검증 이미지 데이터 (shape: 10000 x 28 x 28 x 1)
- test_y.pickle : 검증 정답 데이터 (shape: 10000)
NOTE
왜 파일 확장자로 plckle를 사용했는가?
그 이유는 해당 데이터 중 일부가 4차원 배열이기 때문이다. csv나 text 등의 확장자들은 2차원까지만 저장이 가능하다. 하지만 plckle은 파이썬 객체 자체를 파일로 저장하는 방식이기 때문에 다양한 구조의 데이터들을 비교적 쉽게 저장하고 불러올 수 있다.
다운로드가 완료되었다면 먼저 저장된 데이터가 있는 폴더로 디렉토리를 변경해주어야 한다.
아래의 코드를 입력하여 현재 경로를 확인해보자.
1 | > import os |
확인했을 때 데이터 저장된 위치와 다르다면, 아래의 코드를 사용하여 알맞게 변경해준다.
1 | os.chdir('변경할 주소 입력') |
그 다음 데이터들을 생성한 버킷에 업로드한다. 해당 코드는 아래와 같다.
1 | s3.upload_file('업로드할 파일 이름', '버킷 이름', '버킷에 저장할 이름') |
그후 사이트에 들어가 확인해보면 아래 그림과 같은 변화를 확인할 수 있다.
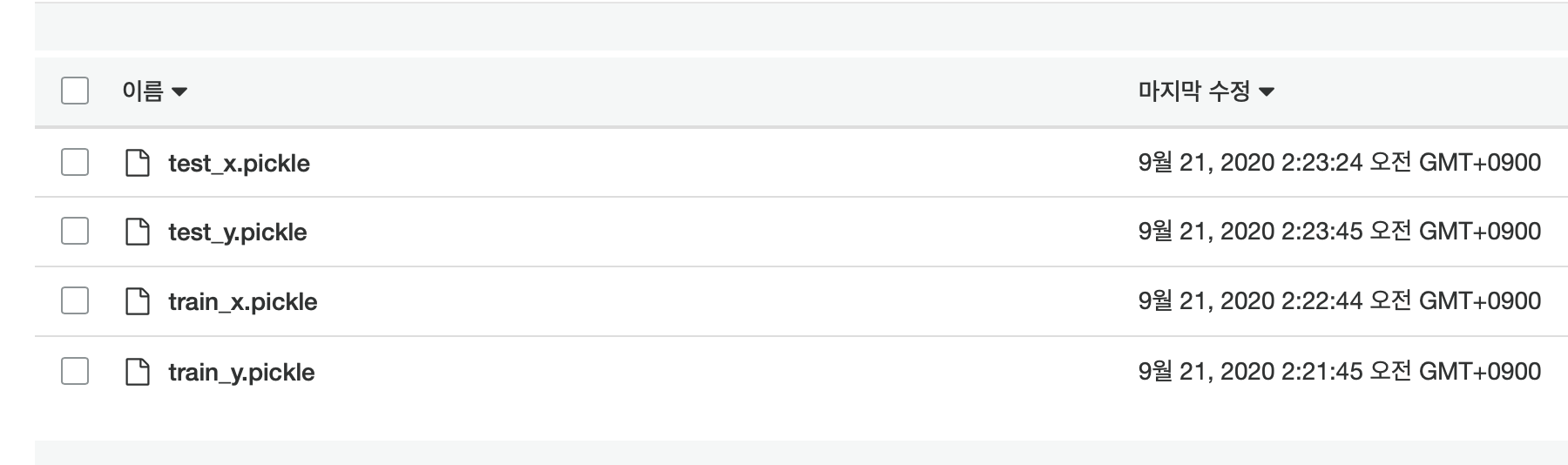
지금까지 커맨드라인에서 S3의 버킷을 생성하고 데이터를 업로드하는 방법을 살펴보았다.