모델 훈련을 위한 Docker image 생성하는 과정을 정리합니다.
Docker란
“개발자 A는 MAS OS 유저이다. 현재 MAS OS에서 개발을 완료하여 서버로 배포하려고 한다. 하지만 Linux기반의 서버에서는 해당 애플리케이션이 작동하지 않는다.”
위의 상황은 실행 환경이 맞지 않아 발생하는 문제이다. 이런 문제를 방지하기 위해서는 어떤 해결 방법이 있을까?
- 개발자가 서버와 똑같은 운영체제를 사용한다.
- 개발자가 가상머신을 사용하여 Linux 기반으로 개발을 진행한다.
- 개발자 컴퓨터와 서버에 Docker를 깔아 컨테이너를 사용한다.
첫 번째 방법은 환경 제약이 너무 많다. 그렇다면 두 번째 방법과 세 번째 방법을 살펴보자.
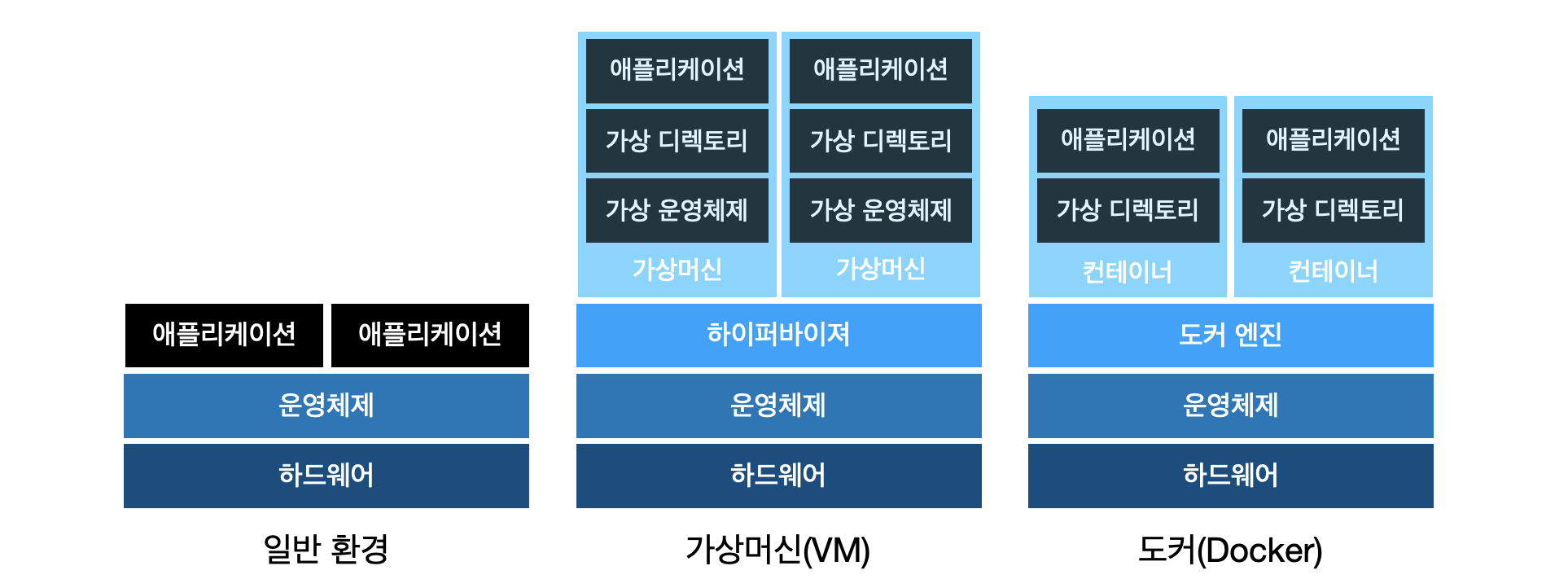
먼저 가상머신(Virtual Machine, VM)은 해당 컴퓨터의 운영체제 위에 가상 운영체제를 구축하여 가상 환경을 만드는 방법이다. 보통 가상머신은 하이퍼바이저를 통해 실제 컴퓨터의 하드웨어 일부를 할당받고 그 위에 원하는 운영체제 쌓아 애플리케이션들을 생성한다. 해당 방법은 완전한 독립된 환경을 구축할 수 있지만, 운영체제도 포함되어 있다보니 배포하는 애플리케이션이 무겁고 다운받는 시간도 오래걸린다.
하지만 도커는 컨테이너 덕분에 비교적 간단하게 애플리케이션을 만들어 배포할 수 있다. 컨테이너란 컴퓨터 내의 독립적인 실행 환경이다. 그렇다면 실행 환경과 가상 환경의 차이점은 무엇일까? 가상 환경은 위에서 설명한 바와 같이 실제 하드웨어의 일부를 할당하여 완전하게 분리된 운영체제를 가진다. 반면 컨테이너는 기존 운영체제를 기반으로 운영체제에 없는 부분만 다운받아 사용한다. 정리하여 가상머신과 도커를 구분한다면 가상머신은 가상 운영체제를 쌓는 반면, 도커는 기존 운영체제를 사용한다는 점이다. 아래의 그림은 일반적인 환경과 가상 머신, 도커의 환경을 보여준다.
Docker Image란
이제 도커 이미지에 대해서 자세히 살펴보자.
이미지(image)는 사용중인 컨테이너의 상태를 그대로 저장하는 방법이다. 예를 들어, 개발자 A가 도커에서 리눅스 기반으로 어떤 애플리케이션을 개발했다고 생각해보자. 그럼 개발자 A는 어떻게 애플리케이션을 배포하는가? 그때 사용되는 방법이 개발자 A의 해당 컨테이너를 이미지로 저장하여 도커 허브(Docker Hub)에 올리는 것이다. 그러면 해당 애플리케이션을 사용하려는 사람들은 이미지를 다운받아 그대로 사용하면 된다. 이미지는 배포를 매우 간단하게 만들어주는 방법으로 실제로 도커 허브에는 수많은 이미지들이 올라와 있다. 우리는 이렇게 이미지를 만드는 과정을 ‘도커라이징(Dockering)’이라고 부른다.
이제 우리가 사용할 도커 이미지를 만들어보자. 도커 이미지를 만들기 위해서는 dockerfile 을 작성해야 한다. dockerfile은 도커 이미지를 만들기 위한 스크립트이다. 아래의 순서대로 dockerfile을 빌드하여 도커 이미지를 생성해보자.
1. 먼저 커맨드라인에서 도커파일을 생성한다
이래의 코드를 커맨드라인에 입력해보자.
1 | vim Dockerfile |
그러면 커맨드라인이 아래와 같이 변경될 것이다.
1 | ~ |
2. 도커파일에 필요한 설정들을 추가한다
1 | FROM ufoym/deepo:tensorflow-py36-cpu |
위 도커파일을 하나씩 살펴보자.
FROM : 해당 이미지의 Base 이미지를 명시한 것이다.
ufoym/deepo는 원래 GPU를 사용하여 딥러닝 모델을 훈련할 때 사용하기 좋은 이미지이다. 해당 프로젝트에서는 AWS에서 프리티어인 CPU를 사용할 예정이기에 특정 이미지만 다운받았다. ufoym/deepo의 모든 버전을 다운받으면 용량이 매우 커져서 오히려 불편하다. 해당 이미지에 대한 정보는 이 페이지에서 확인할 수 있다.MAINTAINER : 도커파일 만든이에 관한 정보를 작성하면 된다.
COPY : 호스트 디렉토리를 복사하여 이미지 안의 디렉토리를 생성한다.
WORKDIR : 도커파일에서 작동하는 명령들을 진행할 디렉토리를 설정한다.
RUN : 해당 이미지로 컨테이너를 생성할 때 작동한다.
CMD : 컨테이너가 생성된 후 해당 스크립트 혹은 명령을 작동시킨다.
위의 정보를 바탕으로 도커파일을 설명한다면
- 먼저
ufoym/deepo:tensorflow-py36-cpu를 가져온다. - 호스트 디렉토리를 복사하여
\app이라는 디렉토리를 만들고 내부로 접속한다. pip라이브러리를 업그레이드하고python3에서model.py를 돌리는 것이다.
이렇게 도커파일을 완성하였다면 아래의 코드를 입력하여 저장한다.
1 | :w Dockerfile |
그러면 현재 디렉토리에 Dockerfile이 저장되었을 것이다.
3. model.py 생성하기
이제 도커에서 훈련할 모델을 생성해야 한다. MNIST 데이터는 비교적 간단한 모델로도 충분하다. 만약 더 복잡한 모델을 훈련하고 싶다면 이 파일에서 해당 모델 스크립트를 작성해주면 된다.
1 | import tensorflow as tf |
다만 도커파일에서 작성해주어야 하기 때문에 해당 파일의 이름을 꼭 model.py로 저장해야 한다.
4. Dockerfile, model.py을 S3에 업로드하기
마지막으로 EC2 인스턴스에서 다운받을 수 있도록 생성한 Dockerfile과 model.py을 S3에 업로드해야 한다. 커맨드라인에서 aws configure을 입력하여 IAM 계정으로 접속한다. 그 다음 아래의 코드를 입력한다.
1 | python3 |
그러면 파이썬이 열리고 boto3 라이브러리를 사용할 수 있다. S3에 접속하기 위해 client를 설정하고, 파일을 업로드 한다.
1 | s3 = boto3.client('s3') |
파일을 S3에 업로드 하는 방법을 자세히 알고 싶다면 3편을 살펴보자.
업로드가 완료된 후 AWS S3 콘솔에 들어가보면 해당 버킷은 아래와 같이 나타날 것이다.