하둡 에코시스템 중 하나인 Hive의 아키텍처에 대해서 공부한 내용을 정리합니다.
지금까지 HDFS, YARN이라는 하둡의 코어 서비스들을 살펴보았다. 사실 두 서비스만 사용해도 하둡 플랫폼을 사용할 수는 있다. 하지만 이전 글에서 말했듯이 사용자의 다양성과 편의를 위해서 많은 에코 시스템들이 등장하였으며, 그 중 대표적인 서비스 중 하나가 바로 하이브(Hive)이다.
Hive
하이브(hive)는 Hadoop용 RDB 서비스이다. HDFS를 사용함에 있어 데이터베이스나 테이블 개념으로 디렉토리를 구성하고 관리하며, 이를 바탕으로 SQL과 유사한 HiveQL이라는 문법을 지원한다. 즉, 자바로 맵리듀스 프로그램을 작성하는 것이 아니라 간단한 sql 문법만으로도 Hadoop에 데이터를 저장하거나 가져올 수 있다. 이렇게만 보면 사용방법은 mysql과 같은 RDB와 매우 유사해보인다.
하지만 스키마를 정의하고 데이터를 입력하는 구조는 기존 RDB와는 다르다. 스키마를 먼저 작성하고 그 다음 데이터를 입력해야 하는 기존 RDB와 달리 하이브는 데이터를 HDFS에 파일단위로 저장한 후에 스키마를 정의하여 데이터를 가져올 수 있다. 하이브는 RDB에 요구되는 스키마 정보들을 metastore에 저장하며, metastore는 다른 DBMS를 사용한다.
Hive Roles
하이브를 구성하고 있는 컴포넌트는 아래 시진과 같다.
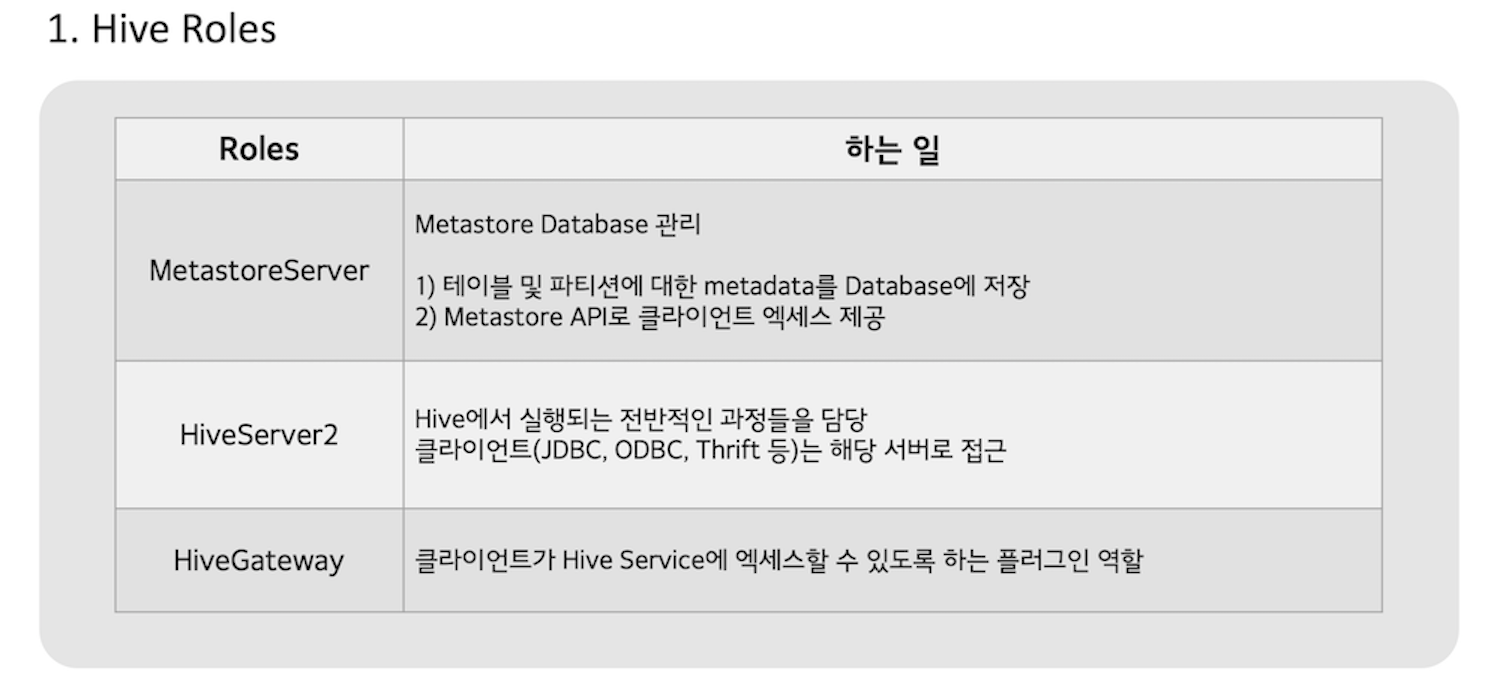
하이브는 크게 metastore 관리, SQL 쿼리 실행의 업무로 나눠지며 이에 따라 컴포넌트들도 분리된다. HiveServer2(HS2)의 경우 하이브 서비스에 대한 모든 클라이언트들의 요청을 받으며, metastore 서버는 HS2에서 요청하는 메타정보들을 API로 제공한다.
Hive Architecture
하이브 아키텍처는 매우 간단하다.
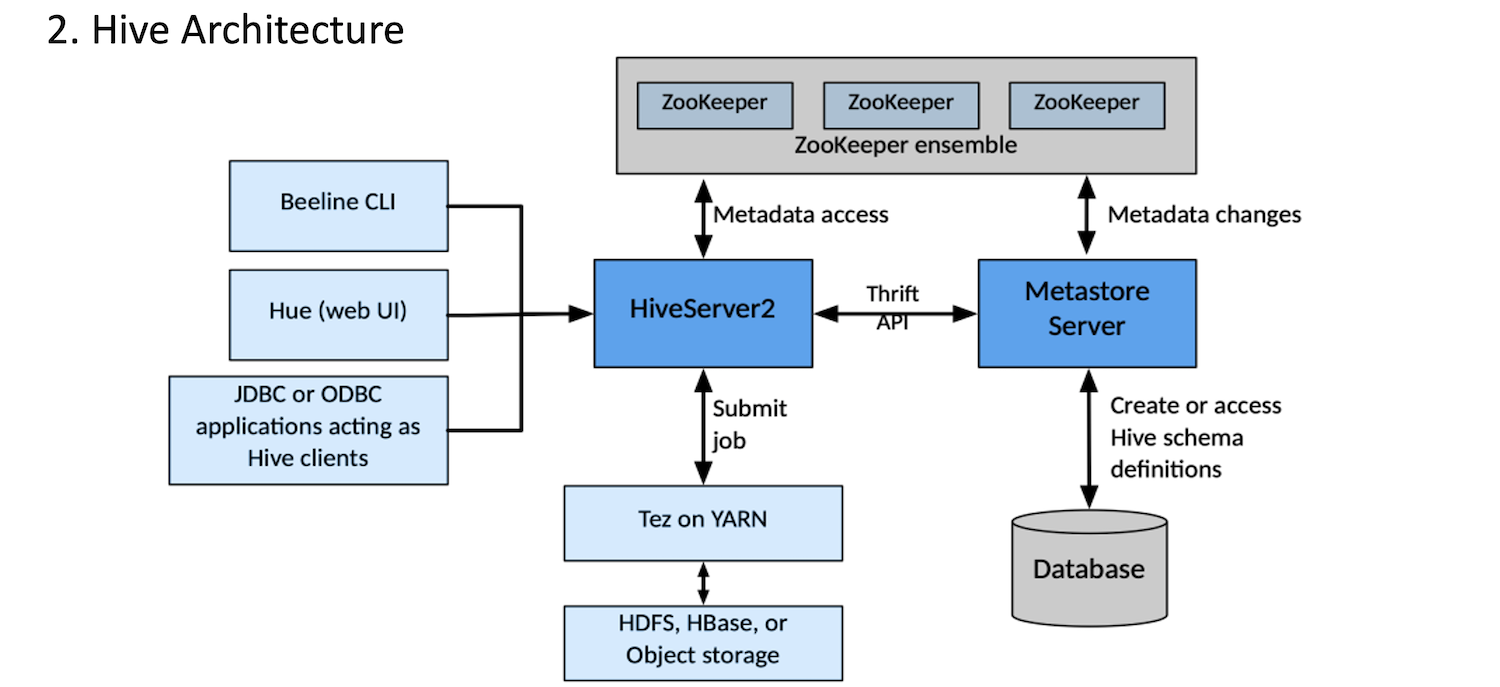
하이브에 접근할 수 있는 방법은 Beeline, Hue, JDBC or ODBC 크게 3가지이다. 여기서 Beeline이란 노드 터미널에서 HS2에 바로 접속할 수 있는 방법이며 Beeline을 사용하면 터미널에서 직접 하이브로 쿼리를 날릴 수 있다. 다음 방법인 Hue는 apache의 오픈소스 서비스 중 하나로 하둡 에코 시스템들을 통합 사용할 수 있는 에디터이다. 마지막으로 JDBC or ODBC는 하둡을 DB로 사용하거나 데이터 IO가 있는 어플리케이션들과 연동할 때 보통 사용되는 방법이다.
NOTE
JDBC or ODBC 란?
특정 언어로 구현된 어플리케이션들이 데이터베이스에 접속할 때 두 언어를 변역해주는 인터페이스의 역할을 한다.
| 용어 | 설명 |
|---|---|
| JDBC(Java DataBase Connectivity) | JAVA 기반 앱들에서만 사용가능한 API |
| ODBC(Open DataBase Connectivity) | 특정 언어와 상관없이 독립적으로 사용가능한 API |
Hive Process
다음으로는 하이브가 작동되는 과정에 대해서 살펴보고자 한다.
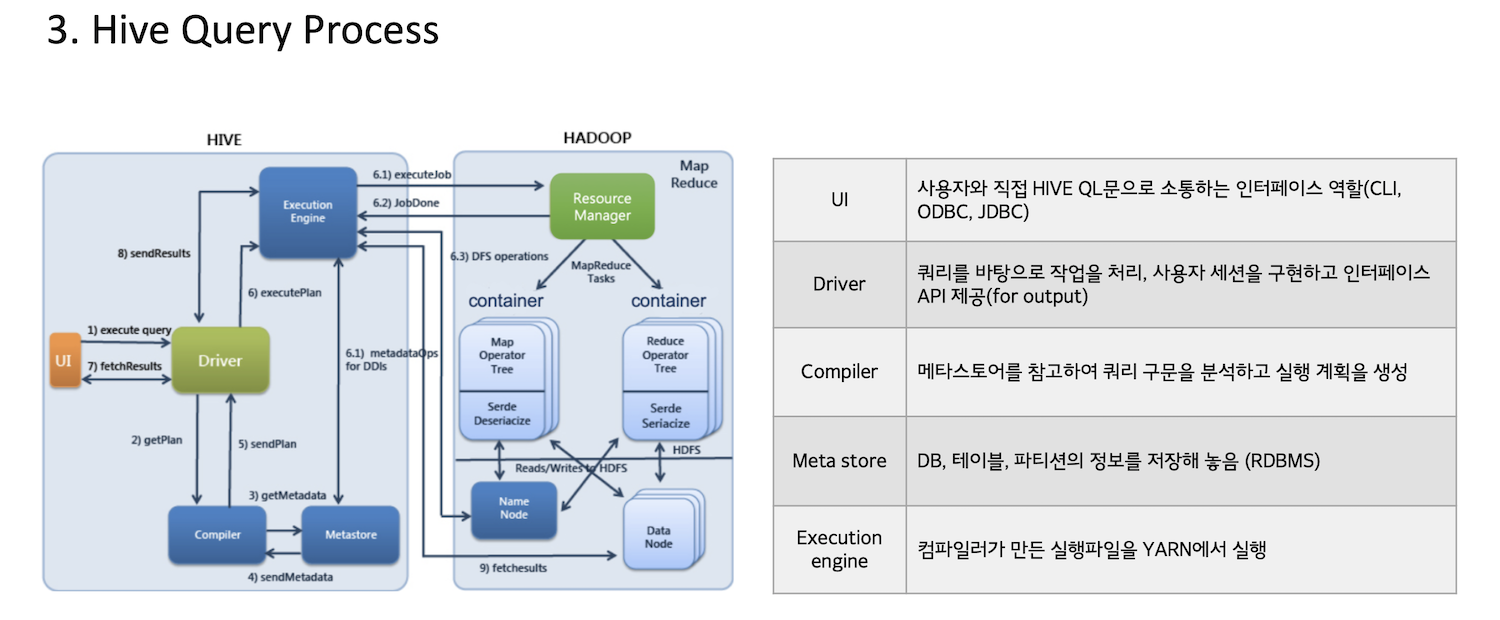
간단하게 생각해보면 하이브는 SQL 쿼리를 받아서 맵리듀스 코드로 변환한 뒤 실행 엔진을 통해 작업을 진행한다. 이 과정들을 진행하기 위해서는 위 사진과 같은 과정들이 새부적으로 진행된다. 이를 정리하면 아래와 같다.
- 인터페이스 단에서 SQL 쿼리를 받은 후 드라이버에게 전달한다. (Hive Thrift)
- 드라이버는 컴파일러에게 SQL 쿼리 컴파일을 요청한다.
- 컴파일러는 Metastore 정보를 사용하여 쿼리에 필요한 데이터들을 가져오는 맵리듀스 프로그램을 작성한 후 드라이버에게 전달한다.
- 드라이버는 실행 엔진에게 해당 작업을 전달한다.
- 실행 엔진은 YARN에게 작업을 요청하여 작업을 진행한 후 그 결과를 가져온다.
- 드라이버는 해당 결과를 인터페이스 단으로 다시 송부한다.
이런 아키텍처를 이해하고 있다면 차후 플랫폼을 사용하다가 발생하는 문제들에 대한 원인을 파악하는 데 도움이 된다. 예를 들어 Hue에서 쿼리를 날렸는데 문제가 발생했다면 HS2와의 세션에서 문제가 생긴 것인지, HS2 내부에서 진행되는 컴파일에서 문제가 생긴 것인지, YARN에서 작업이 돌다가 문제가 생긴 것인지 등을 파악할 수 있다.
Tez engine
초기 Hive는 기본 실행 엔진으로 맵리듀스를 사용하였지만 Hive 3.0부터는 테즈(Tez)를 기본 실행 엔진으로 사용한다. 실행 엔진에 대해서는 따로 글을 작성할 예정이라서 간단하게만 짚고 넘어가보자. 먼저 맵리듀스 엔진과 테즈 엔진의 차이는 다음 사진에 잘 나타나 있다.
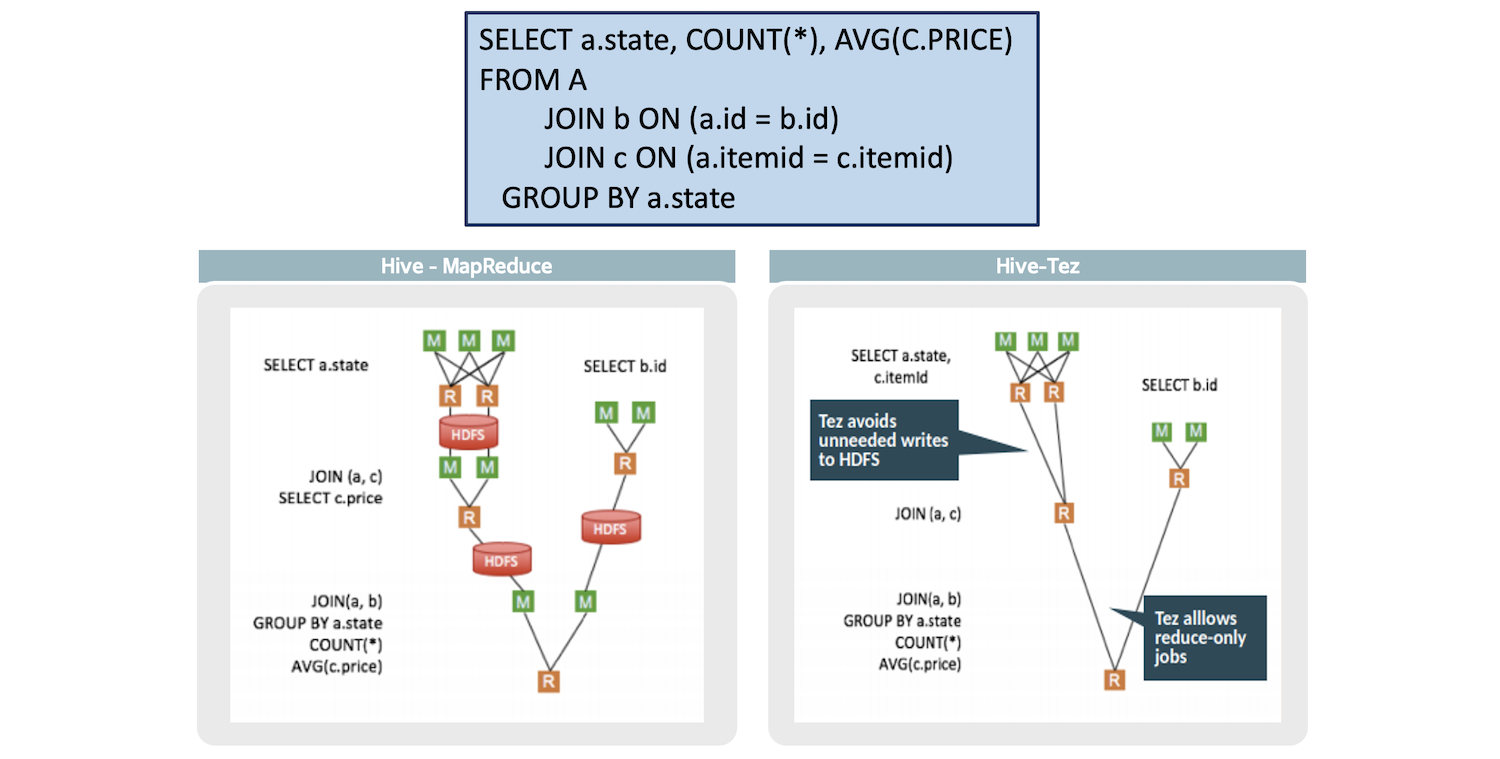
엔진에 대한 자세한 비교는 다음에 자세히 논의해보고자 한다.