Hive에서 주로 언급되는 Schema on Read에 대해서 정리합니다.
시작하기 전에
보통 데이터를 관리하는 시스템들은 크게 Schema on Read, Schema on Write 2가지 타입의 구조를 가진다. 두 타입은 데이터 프로세싱 과정에서 언제 스키마를 정의할 것인지에 따라 나눠지며 일반적으로 사용하는 RDB의 경우 Schema on Write, Hive는 Schema on Read에 해당한다. 두 용어에 대해서 자세히 알아보자.
Schema on Write
Schema on Write는 데이터를 적재하기 전에 스키마를 먼저 생성해야 하는 방식을 말한다. 이를 그림으로 나타내면 아래와 같다.
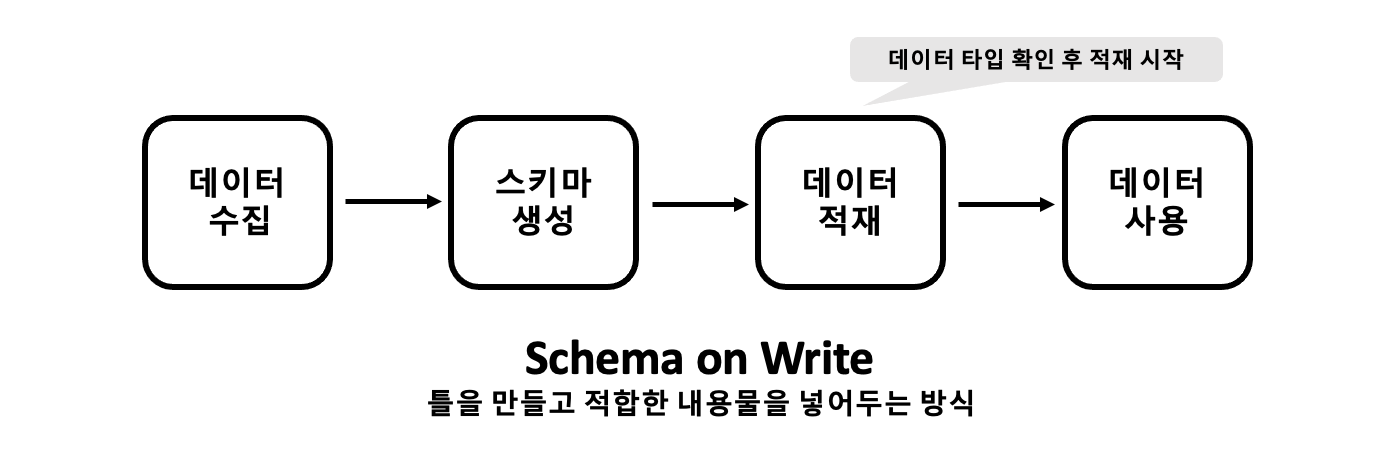
이 방식은 일반 RDB처럼 데이터를 저장하기 위해서는 먼저 스키마를 생성해야 하고 그 다음 데이터를 추가할 수 있는 구조이다. 따라서 스키마에 정의된 데이터 타입이 아닌 데이터를 추가하려고 한다면 에러가 발생한다.
Schema on Read
하지만 하둡 기반의 빅데이터 플랫폼은 구조가 다르다. HDFS라는 파일분산시스템을 통해 데이터를 적재하고 이를 SQL엔진인 Hive가 RDB형태로 가져오는 구조이기 때문이다. 따라서 Hive는 자연스레 Schema on Read 구조를 따를 수 밖에 없다.
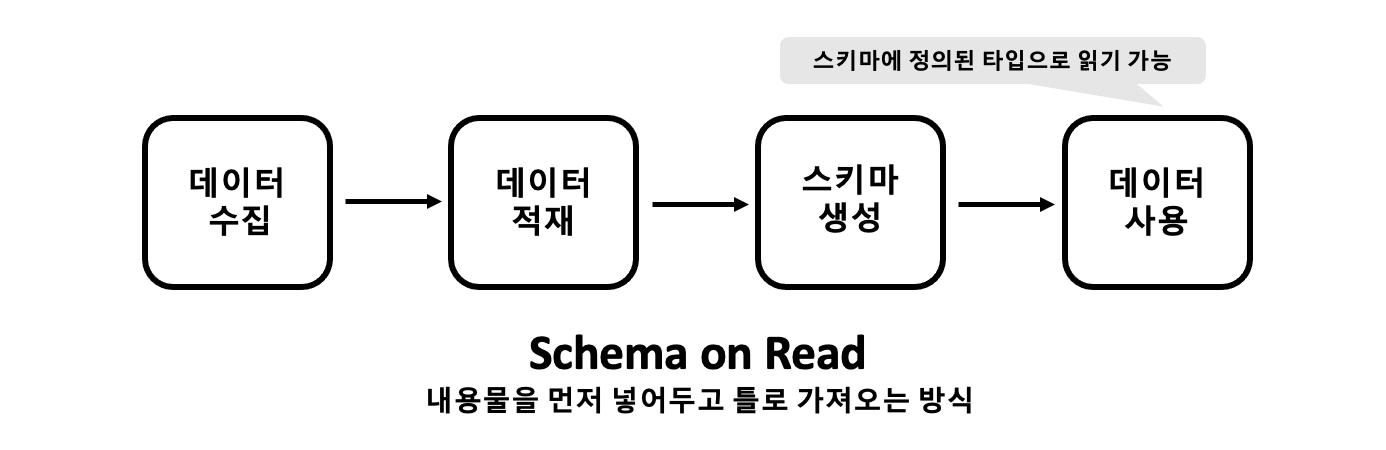
이 방식은 Raw 데이터를 일단 저장한 후 차후에 필요한 스키마를 생성함으로써 데이터를 읽어온다. 따라서 정의된 스키마 데이터 타입과 실제 저장된 데이터 형식은 일치하지 않을 수 있다. 또한 동일한 데이터를 가지고 여러 개의 스키마를 정의할 수도 있다.
비교
두 구조는 각각의 특징이 존재하며, 이를 정리하면 아래와 같다.
| 타입 | Schema on Write | Schema on Read |
|---|---|---|
| 데이터 확인 | 적재 전 | 읽기 전 |
| 적재 속도 | 비교적 느림 | 비교적 빠름 |
| 읽는 속도 | 비교적 빠름 | 비교적 느림 |
| 오류 빈도 | 비교적 낮음 | 비교적 높음 |
| 유연성 | 비교적 낮음 | 비교적 높음 |