LLM을 사용하여 사내가이드 슬랙봇 만드는 방법을 정리합니다.
시작하며
ChatGPT 등장 이후 AI 업계는 큰 변화를 맞이한 것 같다. 딥러닝이 주전공은 아니지만 데이터 업계에 몸담고 있는 이상 어느 정도는 알아야 할 것 같아 사내에서 스터디를 진행하였다. 스터디를 진행하면서 뭐라도 하나 만들어보고 싶던 찰나에 컨플루언스 검색엔진 성능이 너무 좋지 못하다는 의견이 나왔다 (우리 회사는 대부분의 문서를 컨플루언스에서 관리한다). 원하는 정보를 찾기 위해 키워드 기반으로 검색해도 전혀 다른 문서들이 더 많이 반환된다는 것이다.
바로 이거다. 슬랙에서 물어보면 컨플루언스 문서를 보고 알아서 답해주는 비서가 있으면 편할 것 같다. 바로 만들어보자.
무엇을 하려고 하는가
간단하게 사내에서 사용할 사내가이드 슬랙봇을 만들고자 한다.
구조는 다음과 같다.
- 질문 들어온 내용과 유사한 글들을 몇 개 선정
- 선정된 글을 ChatGPT에게 보내 질문에 해당하는 내용만 요약
- 슬랙 API로 요약내용과 글 링크 전달
이를 위해 해야 하는 일들은 다음과 같다.
- 사용할 데이터 수집 및 전처리하기
- 미리 임베딩해서 Vector Database 생성하기
- 유사도 분석 로직 개발하기
- 프롬프트 생성하기
- 슬랙 앱 만들기
본격적으로 개발하기 전에 간단하게 필요한 지식들을 먼저 정리하자. 아래 내용은 중요하다고 생각한 최소한의 설명만을 정리한 것이다.
LLM이란 무엇인가
- Large Language Model, 거대언어모델이라고 불림
- 엄청난 양의 훈련 데이터, 파라미터 셋으로 훈련시킨 모델 -> 엄청난 비용과 에너지 요구됨
- 특정 분야에 최적화된 것이 아니라 대부분의 질문에도 답변을 생성할 수 있음
- 프롬프트를 어떻게 작성하느냐에 따라 답변이 다르게 도출됨
- 파인튜닝(Fine-tuning)을 하면 특정 작업에 더 적합하도록 구성할 수 있음
- 파인튜닝은 훈련 리소스 비용이 방대한 반면 RAG는 가성비로 성능을 높일 수 있음.
RAG란 무엇인가
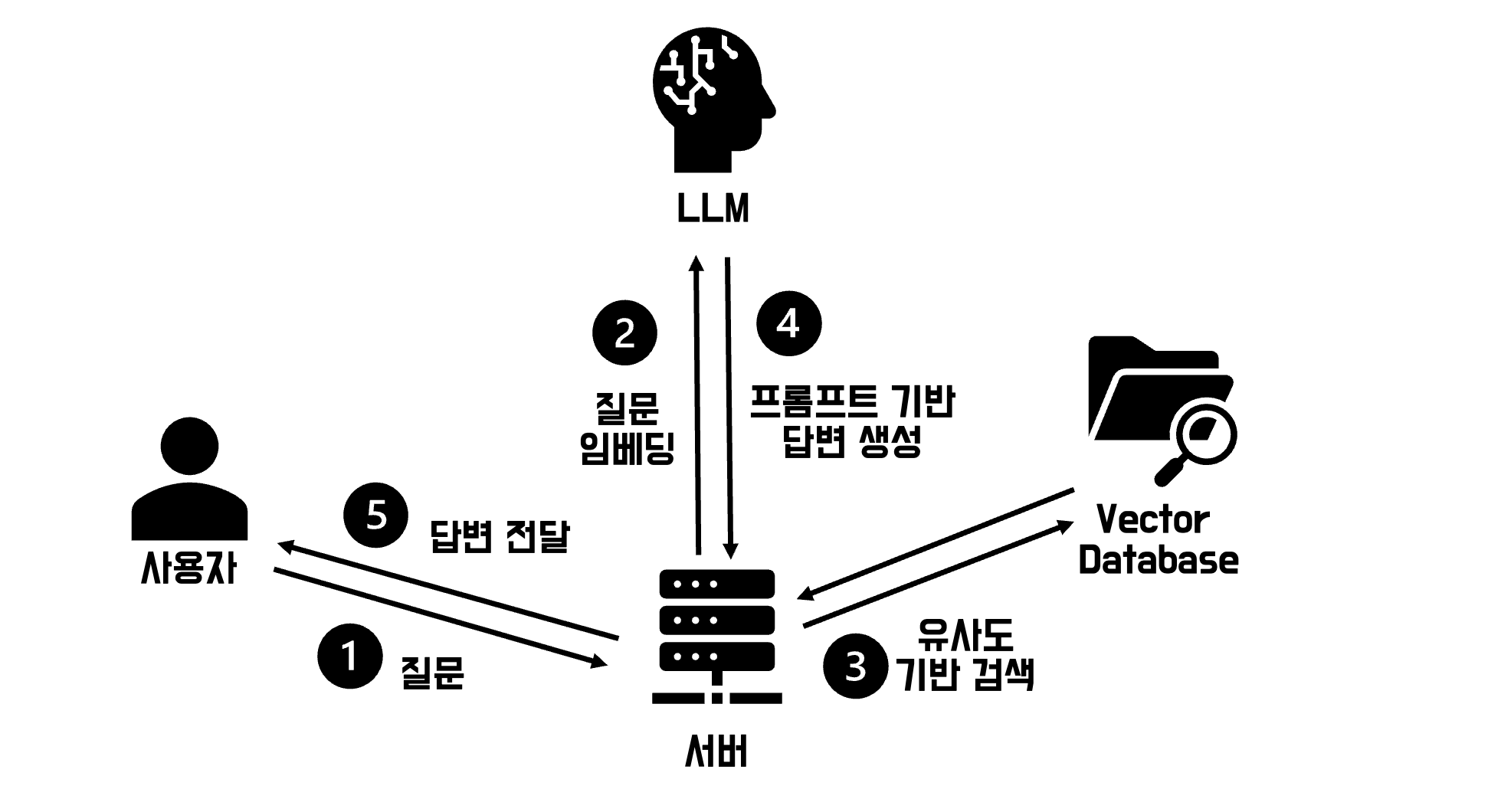
- Retrieval Augmented Generation, 검색증강생성이라고도 불림
- 질문에 적합한 데이터들을 LLM에게 전달하여 이를 기반으로 답변을 도출할 수 있도록 하는 아키텍처
- 보통 검색로직과 답변생성로직, 2개로 나눠짐
- 검색로직: 질문과 Vector Database에 있는 데이터와의 유사도 분석으로 적합한 데이터를 추출
- 답변생성로직: 적합한 데이터 + 프롬프트를 활용하여 LLM 모델로부터 원하는 답변 도출
Vector Database란 무엇인가
- 임베딩된 벡터를 저장하고 쿼리하는 데이터베이스. 핵심 키워드는 인덱스와 임베딩
- 인덱스: PQ, LSH, HNSW 같은 알고리즘들을 사용하여 유사한 벡터를 빨리 쿼리할 수 있도록 만든 자료구조
- 임베딩: 텍스트, 이미지, 오디오 등의 고차원 데이터를 저차원의 벡터 형태로 변환
- 학습 데이터를 임베딩으로 변환하여 저장한 후 질문과 유사도를 계산하여 적합한 데이터를 도출할 수 있음
프롬프트란 무엇인가
- LLM에게 적합한 답변을 얻어내고 잘못된 사용을 제한하기 위한 가이드
- 프롬프트를 제대로 작성하지 않으면 기밀을 유출하거나 잘못된 답변을 도출하기도 함
- 역할을 명확하게 부여하는 방식이 깔끔한 결과를 도출할 수 있음
결론
이제 프로젝트를 진행할만큼의 기본 개념은 알게된 것 같다.
다음 글에서는 본격적으로 슬랙봇을 만들어보자.