유사도 분석이란
유사도 분석은 주어진 데이터나 객체 간의 유사성을 평가하고 비교하는 것을 의미한다. 이는 다음와 같은 분야에서 보통 사용된다.
- 자연어 처리 (Natural Language Processing, NLP): 문서나 문장 간의 유사도를 측정하여 정보 검색, 문서 분류, 텍스트 요약 등에 활용된다. 코사인 유사도, 유클리드 거리 등의 방법을 사용하여 문장 간의 유사도를 측정할 수 있다.
- 이미지 처리 (Image Processing): 이미지 간의 유사성을 측정하여 객체 인식, 이미지 분류, 이미지 검색 등에 활용된다. 이미지의 특징을 추출하여 이를 기반으로 유사도를 계산하는 방법이 사용된다.
- 추천 시스템 (Recommendation Systems): 사용자의 선호도를 파악하여 유사한 항목을 추천하는 시스템에서 사용할 수 있다. 사용자 간의 유사도(협업 필터링 추천 시스템)나 제품 간의 유사도(콘텐츠 기반 추천 시스템)를 측정하여 추천하는데 활용된다.
- 패턴 인식 (Pattern Recognition): 데이터의 패턴을 분석하여 유사성을 파악하는 분야에서도 중요한 역할을 한다.
유사도 계산 방법
유사도를 구하는 방법은 다양하게 존재한다. 어떤 데이터를 사용하는지, 어떤 기준의 유사도를 얻고 싶은지에 따라 선택할 수 있는 적합한 방법은 모두 다르며, 이번 글에서는 대표적인 방법만 간단하게 정리하려고 한다.
자카드 계수
자카드 계수는 비교 데이터의 합집합과 교집합을 사용하여 유사도를 계산하는 방식이다. 수식은 다음과 같다.
위 수식을 해석해보면 특정 기준으로 데이터를 비교했을 때 동일하게 가진 원소의 개수와 서로 다른 원소 개수를 나눠 비율을 구하는 방식이다. 즉, 유사도의 기준은 “서로 얼마나 같은 데이터를 포함하고 있는가”이다. 해당 방법으로 유사도를 구한다면 최대값은 1이며, 최소값은 0이다.
자카드 계수가 적합한 조건은 다음과 같다.
- 간단하게 유사도를 구하고 싶을 때
- 특정 단어 기준으로 유사도를 구하고 싶을 때
- 임베딩(벡터화)를 진행할 수 없을 때
- 비교 데이터의 길이 또는 개수가 일정하지 않을 때
반대로 자카드 계수가 지닌 단점은 다음과 같다.
- 데이터의 빈도를 고려하지 않는다.
- 어휘의 유사성을 고려하지 않는다.
- 음의 상관 관계를 담지 못한다.
유클리드 거리
유클리드 거리는 L2 거리라고도 불리며, 다차원 공간에서 두 점 사이의 최단 거리를 구한다. 수식은 다음과 같다.
여기서 유사도의 기준은 n차원 공간에서의 최단 거리이며, 각 차원의 성분값의 차이의 제곱을 모두 더한 후에 제곱근을 취한 값으로 계산된다. 이는 피타고라스의 정리를 응용하여 계산하는 방식이며, 결과값이 작을수록 두 벡터는 유사하다고 볼 수 있다. 수식 자체가 벡터 성분 차이의 합이기에 벡터의 크기가 다른 경우 제대로된 유사도 결과를 도출할 수 없다. 또한 특정 차원의 값이 이상하게 큰 경우에도 의도하지 않은 가중치가 적용되어 잘못된 유사도를 계산할 가능성이 높다.
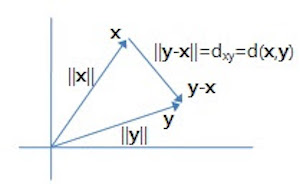
따라서 보통 유클리드 거리를 사용할 때는 정규화 과정을 거치며, 많이 사용되는 정규화 방법은 다음과 같다.
| 이름 | 설명 | 수식 |
|---|---|---|
| 표준화 (Standardization) |
데이터의 각 차원을 해당 차원의 평균으로 빼고, 표준편차로 나누어 데이터를 평균이 0이고 표준편차가 1인 분포로 변환한다. | $z = \frac{x - \mu}{\sigma}$ |
| 최소-최대 정규화 (Min-Max Normalization) |
각 차원을 해당 차원의 최솟값으로 빼고, 최댓값에서 최솟값을 뺀 값을 나눠 모든 차원의 데이터를 [0, 1] 범위로 변환한다. | $z = \frac{x - \min(x)}{\max(x) - \min(x)}$ |
결론적으로 유클리드 거리가 사용되기 적합한 조건은 다음과 같다.
- 데이터의 차원이 동일할 때 (벡터의 길이가 동일할 때)
- 데이터의 차원이 상대적으로 낮을 때
- 데이터의 분포가 균일할 때
- 클러스터링(군집화)가 필요할 때
맨해튼 거리
맨해튼 거리는 L1 거리라고도 불리며, 도시의 블록처럼 가로와 세로로만 이동하여 이동 거리를 측정하는 것과 유사하다. 수식은 다음과 같다.
여기서 유사도의 기준은 n차원 공간에서의 가로 방향과 세로 방향으로의 이동 거리이며, 각 차원의 성분 차이의 절대값을 모두 합한 값이다.
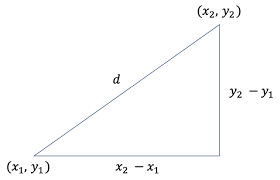
위 사진처럼 유클리드 거리는 각 점의 직선거리라면 맨해튼 거리는 오로지 가로와 세로로만 이동한 거리이다. 이런 방식은 특정 방향으로 이동하면서 얼마나 다른지를 측정하는 데 유용하며, 이미지 유사도나 패턴 분석 등의 데이터에 사용할 수 있다.
결론적으로 다음과 같은 상황일 때는 맨해튼 거리를 사용하는 것이 적합하다.
- 데이터(객체)의 이동 경로를 비교하고 분석할 때
- 도시의 도로 네트워크나 지리 정보와 관련된 데이터일 때
- 텍스트 단어의 빈도, 출현 패턴을 비교할 때
- 그래픽스나 이미지 데이터를 처리할 때
코사인 유사도
코사인 유사도는 벡터 형태인 비교 데이터의 사잇각을 통해 유사도를 계산하는 방식이다. 수식은 다음과 같다.
여기서 잠깐 벡터 내적과 벡터 크기를 모르는 사람들을 위해 간단하게 정리해보자.
| 정의 | 설명 | 예시 |
|---|---|---|
| 벡터 내적 $A \cdot B$ |
각 성분별로 곱해서 더한 값이며, 벡터 간의 방향성을 나타낸다. 두 벡터가 비슷한 방향을 향하고 있다면 각 성분끼리의 곱이 양수가 되며, 다른 방향을 향하고 있다면 각 성분끼리의 곱이 음수가 된다. 따라서 결과값이 최대값이라면 완전히 같은 방향이며, 0이라면 수직, 음수라면 반대 방향임을 알 수 있다. |
$A=(3,4), B=(2,2)$ 일 때, $A \cdot B=(3×2)+(4×2)=14$ |
| 벡터 크기 $\lVert A \rVert, \lVert B \rVert$ |
벡터의 크기는 벡터의 길이를 의미하며, 해당 벡터의 성분을 제곱하여 더한 후 제곱근을 취한 값이다. 만약 $n$차원 벡터라면 n개의 성분을 제곱하여 더한 후 제곱근을 적용하면 된다. 여기서 제곱을 하는 이유는 길이라는 개념이 무조건 양수라서 음수를 제거하기 위함이다. |
$A=(3,4), B=(2,2)$ 일 때, $\lVert A \rVert=\sqrt{3^{2}+4^{2}}=5$ $\lVert B \rVert=\sqrt{2^{2}+2^{2}}=2\sqrt{2}$ |
위 설명에 따라 수식을 해석해보면 두 벡터의 내적을 두 벡터 크기의 곱으로 나눈 값이다. 벡터의 내적은 “두 벡터의 방향성”을 의미하고, 두 벡터 크기의 곱은 “두 벡터의 최대 크기”를 의미한다. 따라서 두 수를 나누면 “정규화된 벡터 유사도” 결과가 도출되는 것이다. 이는 벡터 크기에 유사도가 영향을 받지 않도록 하는 정규화 과정이라고 볼 수 있다.
위 수식의 결과값에 대한 자세한 해석은 다음 그림에서 확인할 수 있다.
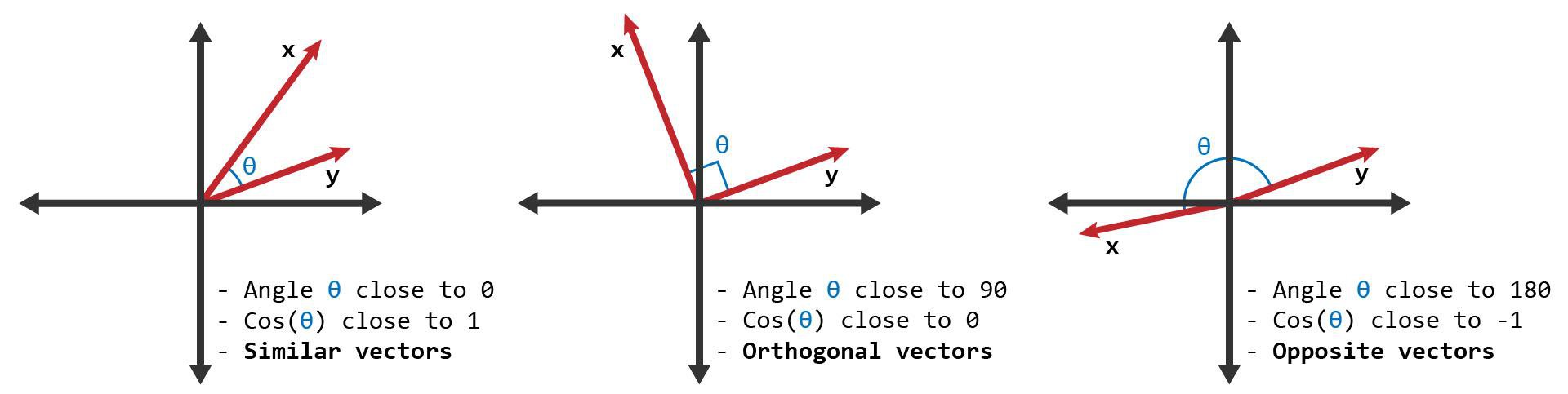
코사인 유사도는 방향으로도 표현되기 때문에 단순히 유사한 정도뿐만이 아니라 서로 반대된 데이터인지도 확인이 가능하다. 또한 각도를 기반으로 유사도를 평가하기 때문에 실제 벡터의 크기에는 큰 영향을 받지 않는다.
결론적으로 코사인 유사도 방법으로 계산한 결과값을 해석한다면 1과 가까울수록 유사한 데이터, 0에 가깝다면 서로 독립된 데이터, -1에 가깝다면 서로 반대의 의미를 가진 데이터라는 것이다.
코사인 유사도가 적합한 조건은 다음과 같다.
- 벡터의 크기가 크지 않을 때
- 벡터의 크기가 다양할 때
- 임베딩 시 벡터 크기의 정규화가 안될 때
- 다양한 차원의 데이터를 사용할 때
피어슨 유사도
피어슨 유사도는 두 벡터 간의 선형 상관 관계를 측정하는 방법 중 하나이다. 수식은 다음과 같다.
여기서 잠깐 상관 관계를 모르는 사람들을 위해 간단하게 정리해보자.
상관 관계란
상관 관계는 두 변수 간의 관련성이 얼마나 강한지를 나타내는 지표이다. 만약 양의 상관 관계라면 한 벡터의 값이 증가할 때 다른 벡터의 값도 증가하며, 이는 두 벡터가 비슷한 방향으로 움직인다는 것을 의미한다. 반대로 음의 상관 관계라면 한 벡터의 값이 증가할 때 다른 벡터의 값은 감소하며, 이는 두 벡터가 반대 방향으로 움직인다는 것을 의미한다.
위 수식은 n차원 두 벡터의 유사도를 구하며, $\bar{A}$와 $\bar{B}$는 각각 벡터 $A$와 $B$의 평균값이다. 위 수식에서 분자는 두 벡터가 얼마나 비슷한 방향으로 움직이는지(상관 관계)를 나타내며, 사실상 피어슨 유사도의 핵심 값이다. 분자의 값이 양수라면 양의 상관 관계, 분자의 값이 음수라면 음의 상관 관계를 도출하기 떄문이다. 분모는 두 벡터의 크기 차이가 유사도에 영향을 미치는 것을 방지하기 위한 역할을 한다.
수식을 잘 보면 코사인 유사도와 비슷한 것을 알 수 있다. 코사인 유사도에서는 벡터 값을 바로 사용했다면 피어슨 유사도에서는 편차를 사용한다. 즉, 각 차원의 평균편차 값을 곱함으로써 방향성을 구하며, 각 벡터 편차들의 크기로 결과값을 조정한다. 따라서 피어슨 유사도는 보통 -1과 1사이의 값을 가진다. 결과값이 1에 가까울수록 두 벡터의 높은 양의 상관 관계를 의미하고, -1에 가까울수록 음의 상관 관계를, 0은 선형적인 관계가 없음을 의미한다.
결론적으로 피어슨 유사도는 다음과 같은 조건에서 사용하면 좋다.
- 연속형 변수 간의 관계를 분석할 때
- 데이터가 정규 분포를 따를 때
- 데이터의 이상치 규모가 작을 때
- 두 벡터의 길이가 다르거나 부분적으로 누락되어 있을 때
- 벡터의 요소가 동일 값일 수 있을 때