Why You Shouldn’t Always Use dropDuplicates for Deduplication in PySpark
This article analyzes why dropDuplicates() is slow for deduplicating large PySpark datasets (due to its first aggregation over all columns and memory overhead), and shares an optimization case study demonstrating how using the row_number().over(Window) approach achieved 37% faster performance.
Motivation
Recently, I had a task to deduplicate a large volume of log data. Initially, without much thought, I used dropDuplicates(), but I was surprised by how slow the processing was.

Given the nature of the task, which required repetitive execution, I wanted to improve the speed as much as possible. So, I experimented with various methods directly. Among them, row_number().over(Window) showed relatively better results.
In this post, I will summarize the comparison results of these two methods under the same data environment.
Experimental Environment
To compare the performance difference based on the deduplication method, the experiment was conducted under the following conditions:
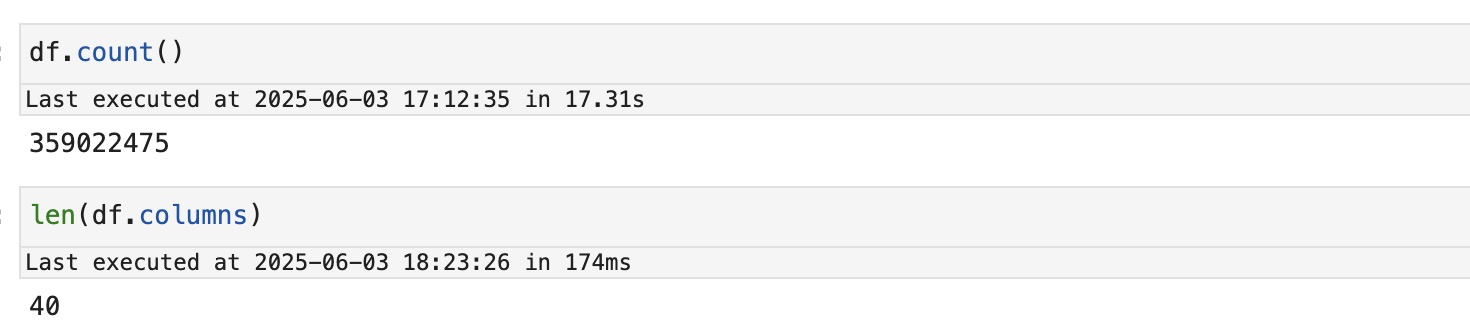
- Data Size: Approximately 350 million rows
- Number of Columns: 40
- Format: parquet → parquet
- Deduplication Key: id column
- Spark Version: 3.4.1
- Execution Environment: AWS EMR
The data used in the experiment was quite large in volume and had a considerable number of columns. Therefore, I judged that it was a condition where the execution time could vary significantly depending on how shuffling and sorting occurred in Spark.
Method A: dropDuplicates()
This is the most commonly used deduplication method. Its usage is simple, and it can be applied directly without separate sorting or window functions.
1 | |
However, examining the actual execution plan reveals that it involves more complex operations than one might expect. Below is a summary of the key parts from the .explain(True) output for df.dropDuplicates(["id"]).
1 | |
From the execution plan, it can be seen that dropDuplicates() internally operates in a manner similar to groupBy + first aggregation. Specifically, the first aggregation function is applied to all columns except the key (id). This means that after shuffling (Exchange) data by the id column, Spark groups by id within each partition and selects the first value from all columns within that group.
During this process, a SortAggregate operation is performed, which is Spark’s optimizer strategy to improve efficiency by sorting the data by the key (id) before performing the aggregation. Thus, both shuffling (Exchange) and sorting (Sort) occur.
Particularly, when the number of columns is large, the first(*) operation, being applied to all columns, requires loading the shuffled data into Executor memory to find the first value for every column. This process can significantly increase the memory usage and GC (Garbage Collection) overhead on each Executor, leading to performance bottlenecks. Consequently, for large datasets, the execution speed often slows down dramatically.
Method B: row_number + Window
This method assigns a sequence number to each group and then keeps only the first row, discarding the rest.
1 | |
The execution plan for the above code is as follows:
1 | |
This method also involves Exchange(shuffle) due to partitionBy("id"), and Sort(sorting) based on id and the orderBy criterion(here, the constant 1) for the Window operation. However, there’s a significant difference compared to the dropDuplicates() method.
When there’s no specific sorting criterion, using orderBy(lit(1)) enables the use of the Window function without requiring a meaningful sort order. Sorting by a constant like lit(1) does not incur the complex sorting cost of actual data, allowing Spark’s Catalyst Optimizer to process it very efficiently or even optimize it in certain cases.
Thanks to this, this method can quickly extract only the desired rows by assigning only the necessary sequence numbers (rn) without unnecessary aggregation and then filtering filter("rn = 1"). This allows for better performance with large datasets.
Experiment Results
Both methods were used to deduplicate the same dataset and then save it to S3.
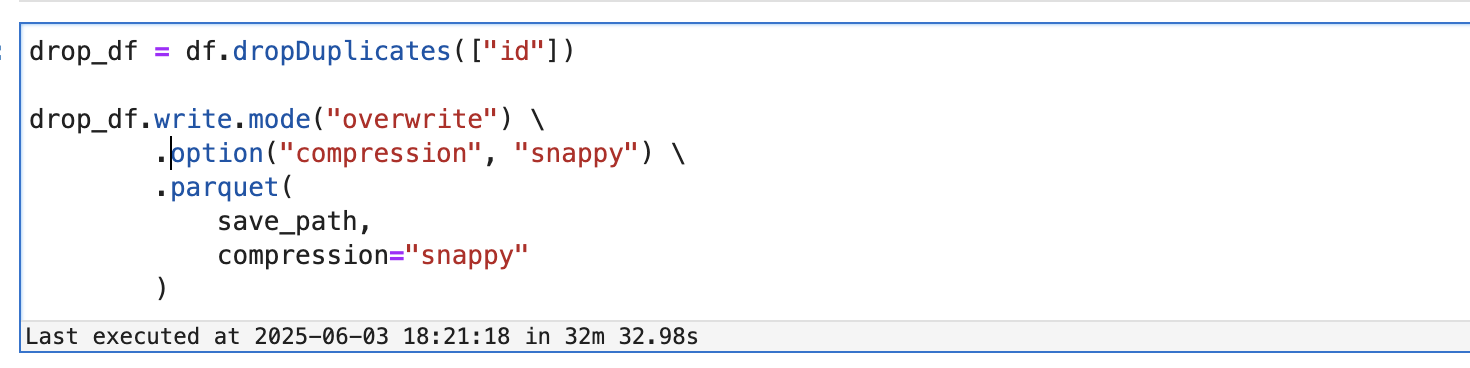
- Processing Time: Approximately 32 minutes
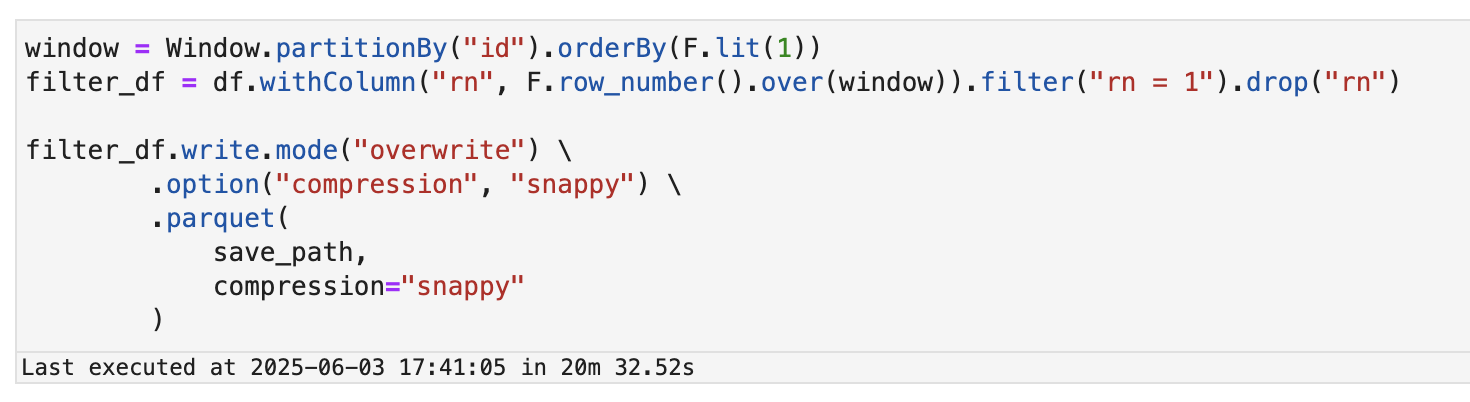
- Processing Time: Approximately 20 minutes
Although it was the same task, the row_number + Window method completed the job approximately 37% faster than dropDuplicates().
Root Cause Analysis
Both methods internally involve shuffling and sorting, but there are crucial differences in their processing approaches.
dropDuplicates() performs a first() aggregation on all columns. This means that while the deduplication criterion is a specific column (id), after receiving the shuffled data, to produce the final deduplicated result, it must load all columns of data into memory to perform the first operation. In this process, Spark consumes more resources as the number of columns increases, and memory usage and GC (Garbage Collection) overhead on each Executor increase rapidly, significantly raising the processing cost. This particularly causes severe bottlenecks in wide tables (tables with many columns).
In contrast, the row_number + Window method shuffles the data and then assigns sequence numbers by sorting based on id and the constant 1. When there’s no specific sorting criterion, orderBy(lit(1)) avoids unnecessary sorting overhead. It then quickly filters for rows where rn is 1 and passes only these desired rows to the next stage. This approach avoids aggregation over all columns and selectively processes only the necessary data, making it a much lighter operation compared to dropDuplicates().
Furthermore, as can be seen from the execution plans above, dropDuplicates() performs SortAggregate and first(…) operations, which internally involve partial aggregation, double sorting (in some Spark versions or situations), and projection of all columns. In contrast, row_number() only assigns necessary sequence numbers, performs a filter, and then drops the rn column, resulting in a much lighter operation for its data size and column count.
In conclusion, when the number of columns is large and the data volume is significant, dropDuplicates() suffers severe bottlenecks due to the first aggregation on all columns and the resulting memory overhead. The row_number + Window method, on the other hand, has a relatively more efficient structure.
Conclusion
dropDuplicates() is a straightforward and intuitive method, making it a reasonable choice when data volume is small or the number of columns is limited. However, for datasets exceeding hundreds of millions of rows or with a large number of columns, the internal operational costs can lead to significant performance degradation.
Conversely, while the row_number().over(Window) method slightly increases code complexity, it can minimize sorting costs and perform deduplication with fewer resources, making it advantageous for large-scale data processing.
Therefore, for repetitive or performance-critical tasks, the row_number + Window method is a strong candidate worth actively considering.