[7/18] 인공신경망 구현: 순전파 알고리즘
해당 시리즈는 프로그래밍 언어 중 하나인 줄리아(Julia)로 딥러닝(Deep learning)을 구현하면서 원리를 설명합니다.
이전 글에서 인공신경망을 학습한다는 것이 어떤 의미인지 살펴보았다. 이번에는 인공신경망을 직접 설계하고 학습하여 손글씨 숫자를 분류하는 인공신경망을 만들 것이다. 인공신경망을 설계하는 것은 앞전에 살펴봤던 도식을 만드는 것이다. 은닉층 개수를 정하여 인공신경망의 깊이를 설정하고, 사용되는 활성화 함수들을 정한다. 그 후 인공신경망을 '어떻게' 학습시킬 것인가를 정해야 한다. 오늘 같이 구현할 '순전파'는 경사하강법에서 기울기를 구하는 방법 중 하나이다.
순전파란
순전파는 기울기를 구하는 과정이 입력값에서 예측값으로 진행되는 것을 의미한다. 즉, 순서대로 이행되는 정직한 미분 알고리즘이다. 우리가 앞서 경사하강법 파트에서 살펴봤던 미분 방법을 사용한다.
순전파 알고리즘의 편미분 원리는 다음과 같다.
- 편미분 대상(가중치와 편향)에 아주 작은 수(1e-50)를 더해준다.
- 손실 함수 값인 \(f1\)을 구한다.
- 편미분 대상(가중치와 편향)에 아주 작은 수(1e-50)를 빼준다.
- 손실 함수 값인 \(f2\) 구한다.
- \(\frac{(f1 - f2)}{2h}\)를 한다. -> 편미분값 완성
- 위의 식 결과를 미분값 객체에 저장한다.
하지만 순전파 알고리즘은 너무 느리다. 그 이유는 매개 변수인 가중치와 편향을 업데이트한 후 다시 처음부터 신경망을 계산하여 손실함수 값을 갱신하기 때문이다. 다음 글에서는 이를 좀 더 빨리 진행할 수 있는 역전파 알고리즘을 살펴볼 것이다.
아래의 수식은 이전 글에서 우리가 만들었던 인공신경망의 프로세스를 나타낸 것이다.
\[\hat{y}=\sigma(h(XW1+B1)\times W2+B2)\]
순전파는 위의 수식에서 합성 함수들 가장 안쪽에 위치한 입력값부터 계산이 진행된다. 즉, 안쪽에서 바깥쪽으로 계산된다고도 볼 수 있다. 도식에서는 왼쪽에서 오른쪽으로 이동하며, 수식에서는 안쪽에서 바깥쪽으로 이동한다.
'MNIST' Project
'MNIST'는 손글씨로 쓴 숫자를 예측하는 인공신경망을 만드는 프로젝트이다. 해당 프로젝트에 대해 더 알고싶다면 이 링크를 참고하면 된다. MNIST는 대부분의 교재에서 사용하는 예시 중 하나이며, 해당 데이터셋이 패키지 안에 준비되어 있다. 먼저 아래의 코드를 입력해서 데이터를 가져오자.
1 | |
해당 데이터의 입력값 train_x는 \(28 \times 28\) 이미지 데이터가 60000개 들어 있으며, train_y는 정답 숫자가 \(60000 \times 1\) 형태로 들어 있다. 우리는 이를 신경망 모델에 알맞게 전처리해주어야 한다. 특히 train_y는 7이나 8같은 숫자로 들어가 있는데 이를 '원-핫 인코딩'형태로 변환해야 한다. 이를 위해 아래의 함수를 먼저 정의하자.
Note 원-핫 인코딩이란? 원-핫 인코딩은 숫자의 형태를 분류하기 위해 사용되는 데이터 형태로 7을 [0,0,0,0,0,0,0,1,0,0]로 변경해준다.
1 | |
위의 함수를 사용하면 숫자로 입력된 train_y가 원-핫 레이블로 변경된다.
1 | |
이제 신경망 모델을 학습하기 위해 필요한 데이터는 모두 준비되었다. 우리가 만들 신경망은 이전 글에서 정리했던 '2층 신경망(TwoLayerNet)'이다. 신경망 모델에서는 네트워크에서 가중치와 편향이 계속 업데이트되어야 하기 때문에 딕셔너리로 정의한다. 만약 딕셔너리에 대해서 모르거나 더 알고 싶다면 해당 글을 참고하자. 또한 네트워크가 정확히 무엇인지 궁금하다면 이전 글을 참고하면 된다.
1 | |
가중치를 할당할 딕셔너리를 정의하였다. params는 기존 매개 변수를 저장하며, grads는 매개 변수의 미분값들을 저장한다. 이제 가중치와 편향의 초기값을 생성하는 함수를 정의하자.
1 | |
위의 함수는 입력 데이터의 행렬 크기, 은닉층의 행렬 크기, 결과값의 행렬 크기를 받아서 그에 알맞는 가중치와 편향 행렬을 생성해준다. 가중치는 오버피팅을 막기 위해 가장 작게 셋팅하는 것이 좋기 때문에 weight_init_std을 곱해준다. 가중치인 W1, W2는 정규분포를 따라 랜덤 수를 생성해주는 randn()를 사용하였으며, 편향인 b1, b2는 초기값인 크기에 맞게 제로 행렬로 만들어준다. 제로 행렬을 만드는 방법은 zeros()를 사용한다.
우리가 사용하는 데이터는 입력값이 \(60000 \times 784\)이며, 결과값은 \(60000 \times 10\)이다. 따라서 W1은 \(784 \times 50\)이며, W2는 \(50 \times 10\)이다. b1은 \(1 \times 50\)이고, b2는 \(1 \times 10\)이다. 따라서 다음과 같이 함수를 사용하면 알맞은 가중치와 행렬 초기값을 만들 수 있다.
1 | |
초기값 설정이 끝났다면 이제 신경망을 학습할 차례이다. 학습을 진행하기 전에 필요한 변수들을 미리 세팅해준다.
1 | |
train_loss_list는 학습이 진행되는 동안 제공되는 손실 함수의 값을 저장할 리스트이다. 모델의 정확도 또한 accuracy에 저장하여 값이 변화하는 과정을 살펴볼 예정이다.
지금부터는 순전파 기반 경사하강법에 사용되는 함수들을 정의할 것이다. 대부분의 함수들은 우리가 이전 글들에서 살펴봤던 원리와 같으며, 단지 신경망 모델에 맞게 부분적인 수정이 이루어졌다.
먼저 기본적인 활성화 함수를 정의한다. 우리는 이번 신경망 모델에 시그모이드와 소프트맥스를 사용할 예정이다.
1 | |
시그모이드 함수는 그대로 사용하며, 소프트맥스의 경우는 배치 데이터에 사용하는 함수를 따로 생성해준다. 배치 데이터는 각 행이 하나의 이미지이기 때문에 행 하나의 요소 합이 1이어야 한다. 위의 softmax()는 각 행 별로 softmax_single()를 계산하여 배열로 반환한다.
Note 배치(batch)란? 배치는 모델이 한번에 처리하는 데이터의 개수를 의미한다. 예를 들어 MNIST 데이터를 본다면, 입력데이터 \(1 \times 784\)는 하나의 이미지이다. 만약 모델에 투입하는 입력데이터가 \(100 \times 784\)라면 이미지 100개를 한번에 사용한 것이며, 이는 배치 데이터이다.
그 다음 예측값 \(\hat{y}\)을 반환하는 predict()를 정의한다.
1 | |
predict()는 params에 있는 초기값 가중치와 편향을 사용하여 계산한다.
1 | |
loss()는 예측값을 계산하고 손실 함수의 결과까지 도출해주는 함수이며, 손실 함수로는 '교차 엔트로피 오차'를 사용하였다. cross_entropy_error()은 배치데이터 손실함수 값의 평균을 제공할 수 있도록 수정하였다.
1 | |
기존의 numerical_gradient()는 매개 변수로 f()와 미분 대상인 x값만 받았다. 하지만 우리가 적용하려는 loss()는 매개 변수가 x, t로 2개가 들어가기 때문에 이 또한 numerical_gradient()의 매개 변수로 추가하였다. 그 다음 loss()에서 편미분되는 변수가 가중치와 편향이기 때문에 이 또한 매개 변수로 추가하였다.
1 | |
위의 TwoLayerNet_numerical_gradient()는 가중치와 편향을 모두 편미분하여 grads에 값을 저장한다.
1 | |
SGD()는 '확률적 경사하강법'으로 기존 가중치와 편향에서 '학습률 \(\times\) 편미분값'을 빼서 갱신한다.
1 | |
마지막으로 정의할 함수 evaluate()는 정확도를 계산한다. 정확도란 실제 실험데이터들을 사용하여 해당 신경망 모델이 얼마나 맞추는지를 확률로 반환한다. 이후 신경망을 직접 학습시키고 정확도를 확인할 것이다.
이제 학습을 진행하기 전에 배치 사이즈와 학습률, 반복 횟수를 지정한다. 보통 학습률은 0.01이나 0.1을 사용한다. 또한 배치 사이즈는 입력 데이터의 형태에 따라 최적화된 크기가 다르지만 이번에는 임의로 배치사이즈를 100으로 지정할 것이다. 그리고 반복 횟수는 100개의 배치데이터 기준으로 1에폭(epoch)인 600을 지정하였다. 에폭이라는 기준에 대해 자세히 알고 싶다면 아래 Note를 확인해보자.
Note 에폭이란? 에폭(epoch)은 훈련데이터 전체의 개수를 의미한다. MNIST 데이터를 예시로 본다면 훈련데이터는 60000개이다. 배치 사이즈가 100인 경우 한번에 100개의 훈련데이터가 사용되므로 모델에 1에폭을 훈련시키려면 600번을 반복해야 한다.
1 | |
이제 모든 준비가 완료되었다. 아래의 코드를 입력하여 학습을 실행해보자.
1 | |
위의 코드는 순전파 기반 경사하강법을 구현한 것이다. 프로세스는 다음과 같다.
먼저 입력 데이터 60000개 중에 100개를 무작위로 뽑아서 배치 데이터셋을 생성한다.
그 다음 가중치와 편향을 편미분한다.(순전파)
grads에 가중치와 편향의 편미분 값들을 저장한다.기존 신경망인
params의 가중치와 편향에서 '학습률 \(\times\) 편미분값'을 빼서 갱신한다. (SGD)갱신한 가중치와 편향으로 다시 손실 함수의 값을 구한 후
train_loss_list에 추가한다.해당 모델을 사용하여 실제 실험데이터를 얼마나 맞추는지 확률을 계산하고,
accuracy에 추가한다.iters_num만큼 위의 프로세스를 반복한다.
편미분을 진행하는 파트에서 순전파는 역전파보다 시간이 매우 많이 소요된다. 따라서 비교적 시간이 여유로울 때 코드를 진행하기를 추천한다.
위의 학습 결과는 다음과 같다.
1 | |
100 단위의 배치 데이터를 600번 반복한 결과, 처음 2.29였던 손실 함수 값이 0.86까지 떨어졌다. 이는 오답률이 많이 감소되었다는 것을 의미한다. 시간은 대략 17600초가 걸렸으며, 환산해보면 약 5시간 정도 소요되었다.
위의 학습 과정에서 저장했던 train_loss_list와 accuracy를 그래프로 나타내보자.
1 | |
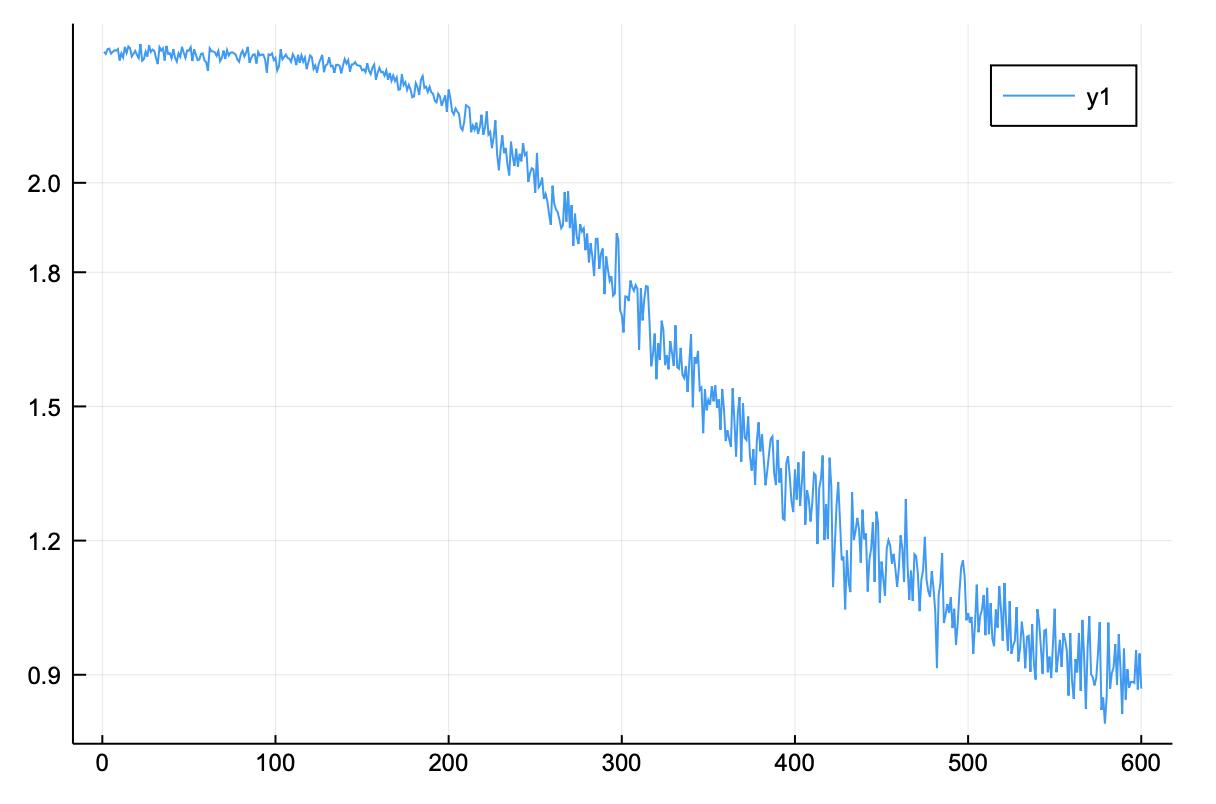
저장된 손실 함수 값을 그래프로 그려본 결과, 지속적으로 감소하는 양상을 확인할 수 있다.
1 | |
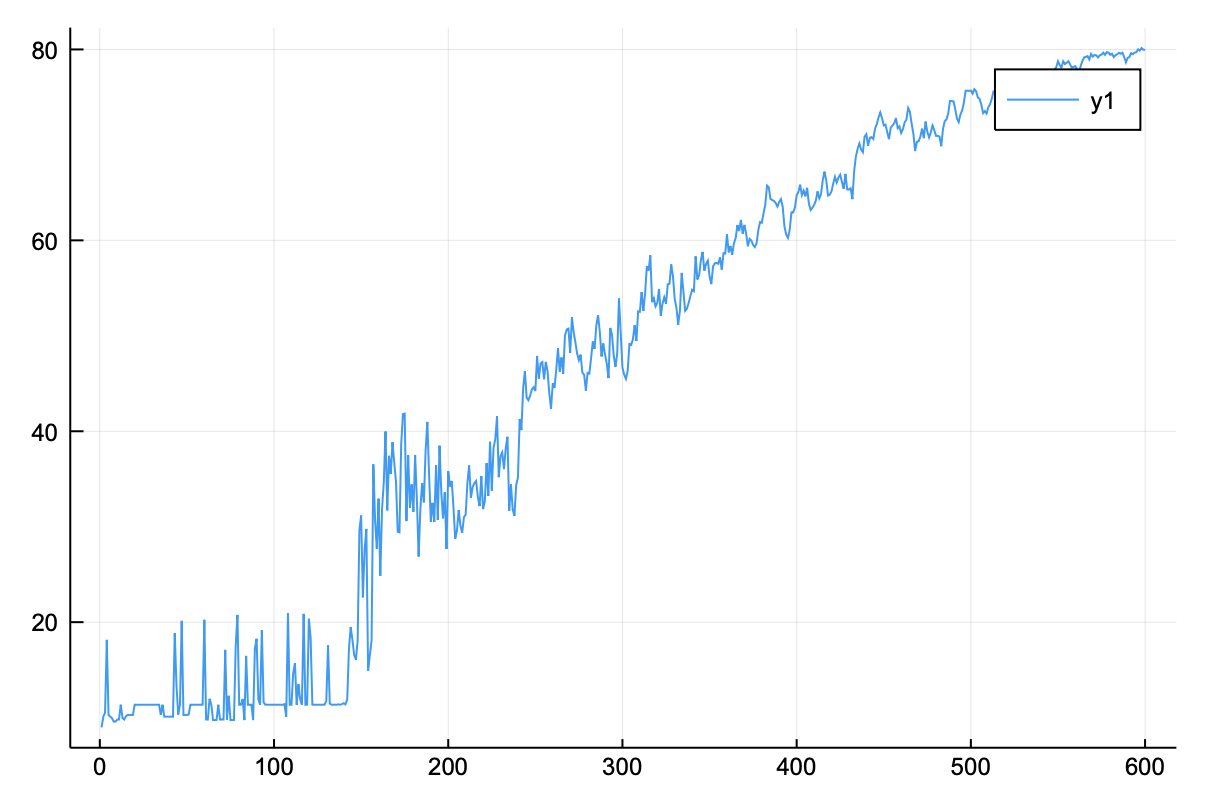
저장된 정확도 또한 계속 상승하는 것을 볼 수 있다. 가장 높은 정확도는 아래의 코드를 통해 확인하자.
1 | |
정확도는 80%를 웃돈다. 여기서 추가로 더 학습하면 정확도는 90%도 넘을 수 있다.
위의 코드를 돌려보면 알겠지만 순전파는 매우 느리다. 아마 1에폭을 돌리면 더이상 학습을 진행하고 싶지 않을 것이다. 하지만 학습을 더 진행하고 싶진 않지만 90%가 넘는지 확인하고 싶은 이들을 위해 순전파로 3에폭을 돌려보았다. 결과는 다음과 같다.
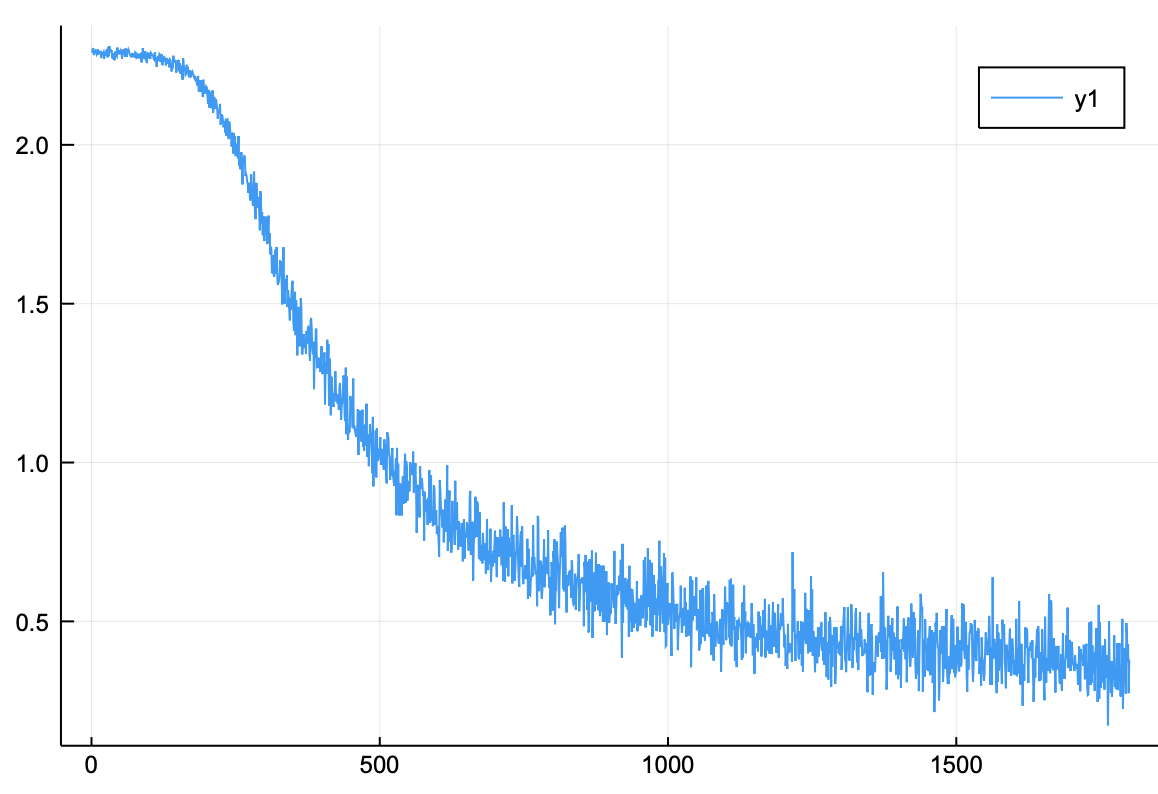
손실 함수 그래프이다. 손실 함수의 값이 0.5 아래로 떨어진 것을 확인할 수 있다.
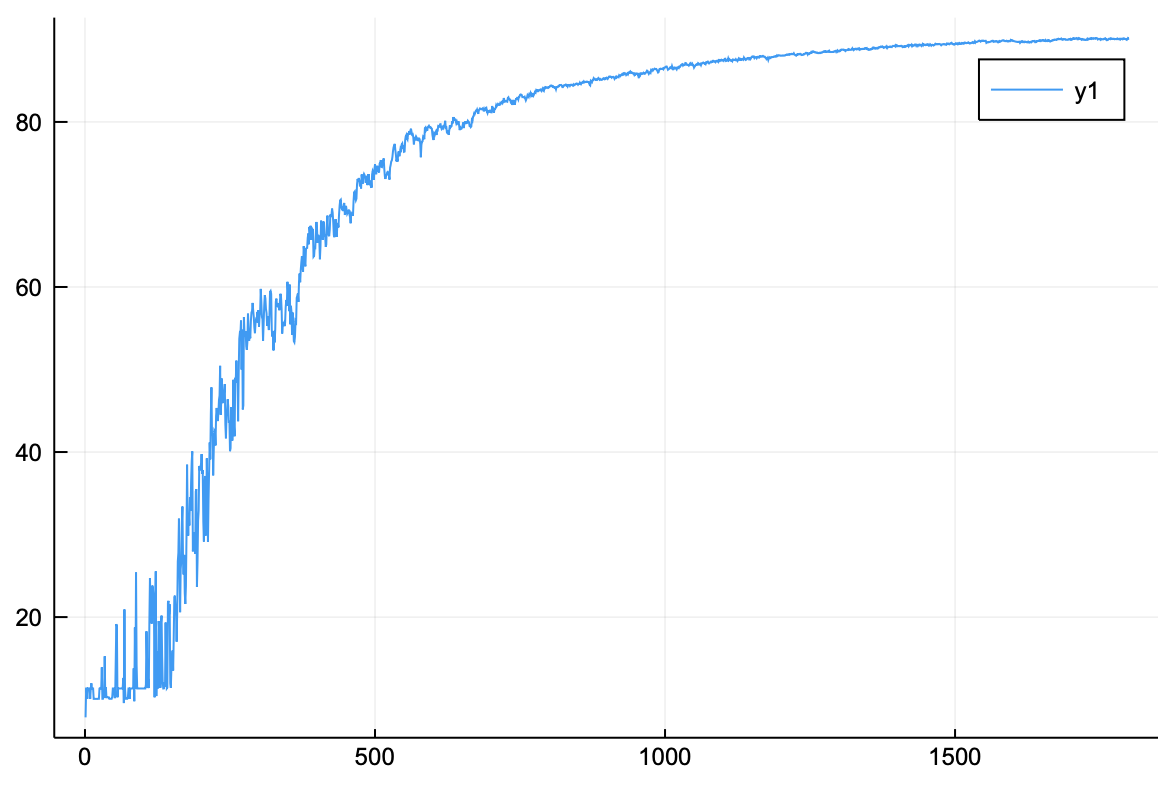
정확도는 80%를 훨씬 넘었다. 가장 높은 정확도를 확인하기 위해 아래의 코드를 입력해보자.
1 | |
정확도가 90%가 넘은 것을 확인할 수 있다.
순전파는 반복되는 매 횟수마다 활성화 함수를 미분하기 때문에 시간이 오래 걸린다. 그렇기에 실상 사용되는 미분법은 아니지만, 신경망의 원리를 파악하기 위해서는 알아야 한다. 다음 글에서는 5시간을 3분으로 줄여주는 마법같은 역전파를 살펴볼 것이다.