해당 시리즈는 프로그래밍 언어 중 하나인 줄리아(Julia)로 딥러닝(Deep learning)을 구현하면서 원리를 설명합니다.
역전파 알고리즘 구현
이전 글에서 순전파 알고리즘을 사용하여 구현했던 'MNIST' 프로젝트를 역전파로 구현할 것이다. 'MNIST' 프로젝트에 대한 자세한 사항은 이전 글 에 있으니 먼저 읽어보고 오자. 특히 줄리아에서 MNIST 데이터셋을 불러오는 방법도 이전 글에 있으니 참고하기를 바란다.
역전파 알고리즘은 다음과 같은 순서로 진행된다.
초기값과 매개 변수 설정
역전파 알고리즘에 필요한 함수 정의
역전파 알고리즘 - 신경망 계산 (순전파 방향)
역전파 알고리즘 - 매개 변수 기울기 구하기 (역전파 방향)
매개 변수 갱신
3번 - 5번 과정을 횟수만큼 반복
초기값과 매개 변수 설정
1 2 3 4 5 6 7 8 9 10 11 12 params = Dict ()Dict ()function making_network(input_size, hidden_size, output_size, weight_init_std =0.01 )"W1" ] = weight_init_std * randn(Float64 , input_size, hidden_size)"b1" ] = zeros(Float32 , 1 , hidden_size)"W2" ] = weight_init_std * randn(Float64 , hidden_size, output_size)"b2" ] = zeros(Float32 , 1 , output_size)return (params)end 784 , 50 , 10 )
매개 변수인 가중치와 편향을 설정하였다. 만약 초기값을 설정하는 방법을 자세히 알고 싶다면 이전 글 에서 확인할 수 있다.
역전파는 신경망 계산이 진행될 때의 변수 값을 저장해서 매개 변수의 기울기를 구할 때 사용한다. 따라서 각각의 변수 값을 저장해두는 저장소가 필요하다. 우리는 이를 구조체로 설정할 것이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 mutable struct dense_layerend mutable struct Sigmoidend mutable struct ReLuend mutable struct SoftmaxwithLossend 0 ,0 )0 ,0 ,0 ,0 ,0 )0 ,0 ,0 ,0 ,0 )0 )0 )
각 층을 기준으로 구조체를 만들어준 후, 초기값을 셋팅하였다. 이제 학습 시 신경망 계산이 진행되면서 초기값들이 갱신될 것이다.
역전파 알고리즘에 필요한 함수 정의
이제 역전파 알고리즘에 사용되는 함수를 정의할 것이다. 역전파 알고리즘에서는 신경망 계산 시 변수 값들을 저장해야 하기 때문에 순전파 함수와는 약간 다르다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function cross_entropy_error(y,t)1e-7 1 ])return (-sum(log.(y.+delta).*t) / batch_size)end function sigmoid(x)return 1 /(1 +exp(-x))end function softmax_single(a)end function softmax(a)return (transpose(hcat(temp ...)))function evaluate(test_x,test_y)1 ) .== test_y)/size(test_x)[1 ])return (temp * 100 )end
위의 함수들은 순전파 알고리즘에서 사용했던 함수와 똑같다. 이는 역전파 알고리즘 신경망 계산 파트에서 사용된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 function SoftmaxwithLoss_forward(x,t)return lossend function SoftmaxwithLoss_backward(result,dout=1 )1 ]return dxend
역전파에서는 소프트맥스 함수와 손실 함수를 같이 사용한다. 그 이유는 간단하다. 미분했을 때의 수식이 훨씬 간편해진다. 위의 코드를 보면 알 수 있듯이 소프트맥스와 손실 함수를 같이 미분하면 \(\hat{y}_k - t_K\) 라는 간단한 식이 도출된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 function dense_layer_forward(dense,x,w,b)return calend function dense_layer_backward(dense, dout)Array (dense.w'))Array (dense.x'), dout)Array (sum(eachrow(dout))')return dxend
dense_layer는 입력값과 가중치를 곱한 후, 편향을 더해주는 층(layer)이다. 역전파에서는 가중치와 편향, 입력값 각각의 편미분을 진행하였다.
1 2 3 4 5 6 7 8 9 10 function sigmoid_forward(Sigmoid, x)return dxend function sigmoid_backward(Sigmoid, dout)1.0 .- Sigmoid.z) .* Sigmoid.zreturn dxend
시그모이드 함수는 신경망 계산 시에 결과값을 저장해두어야 하기 때문에 구조체 Sigmoid에 저장한다. 그후 역전파 함수에서 가져와 미분을 진행한다.
1 2 3 4 5 6 7 8 9 10 function relu_forward(Relu, x)0 return xend function relu_backward(Relu,dout)return dxend
ReLU 함수의 경우 신경망 계산에서 음수인 입력값은 전부 0으로 변경되는데 이를 미분에서도 그대로 구현해주어야 한다. 따라서 0으로 변경되는 위치를 mask에 저장해두었다가 역전파 과정에서 사용한다.
1 2 3 4 5 6 function SGD(params,grads)for key in keys(params)end return paramsend
SGD()는 확률적 경사하강법을 구현한 함수로 매개 변수 갱신을 진행한다.
역전파에 필요한 변수 정의
그다음 역전파에 필요한 변수들을 정의한다.
1 2 3 4 5 6 train_loss_list = Float64 []Float64 []1 ]100 0.1 600
역전파 알고리즘
역전파를 구현하기 전 준비는 모두 끝났다. 이제 알고리즘을 작동시켜보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @time begin for i in 1 : iters_num1 :train_size, 100 )"W1" ],params["b1" ])"W2" ],params["b2" ])"W2" ] = dense2.dw"b2" ] = dense2.db"W1" ] = dense1.dw"b1" ] = dense1.db"NO.$i : " )end end
이전에 구현했던 순전파와 똑같이 1에폭 학습을 진행한다. 위 알고리즘의 프로세스는 다음과 같다.
먼저 입력 데이터 60000개 중에 100개를 무작위로 뽑아서 배치 데이터셋을 생성한다.
신경망 계산을 통해 역전파에 필요한 값들을 구조체의 인스턴스에 저장한다.
역전파 과정을 진행하여 미분값들을 도출하고 저장한다.
역전파로 얻은 미분값들을 사용하여 매개 변수를 갱신한다.
갱신한 가중치와 편향으로 손실 함수의 값을 구한 후 train_loss_list에 추가한다.
해당 모델을 사용하여 실제 실험데이터를 얼마나 맞추는지 확률을 계산하고, accuracy에 추가한다.
iters_num만큼 위의 프로세스를 반복한다.
위의 알고리즘을 구현한 결과는 다음과 같다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 NO.1 : 2.2850101570382737 .2 : 2.2850446322621685 .3 : 2.2877722109055973 .4 : 2.295771461232412 .5 : 2.291090515421742 .6 : 2.292813792030001 .7 : 2.2923265665429757 .8 : 2.2667084942417035 .9 : 2.277930664348887 .10 : 2.2888958183165564 .590 : 0.902825806105116 .591 : 0.8906761172487827 .592 : 0.7956979255136711 .593 : 0.9324068193760575 .594 : 0.8170173565209091 .595 : 0.8525111451656349 .596 : 0.8223313778429329 .597 : 0.8781017363141977 .598 : 0.8522437572097963 .599 : 0.7652566853974547 .600 : 0.8263608966251377 19.715322 seconds (39.55 M allocations: 13.826 GiB, 7.82 % gc time)
100 단위의 배치 데이터를 600번 반복한 결과, 처음 2.28였던 손실 함수 값이 0.82까지 떨어졌다. 이는 오답률이 많이 감소되었다는 것을 의미한다. 시간은 대략 20초 정도 소요되었다. 순전파와 비교해봤을 때 매우 빠른 것을 확인할 수 있다.
역전파 알고리즘에서 저장했던 train_loss_list와 accuracy를 그래프로 나타내보자.
1 2 3 using Plots1 ,length(train_loss_list),step=1 )
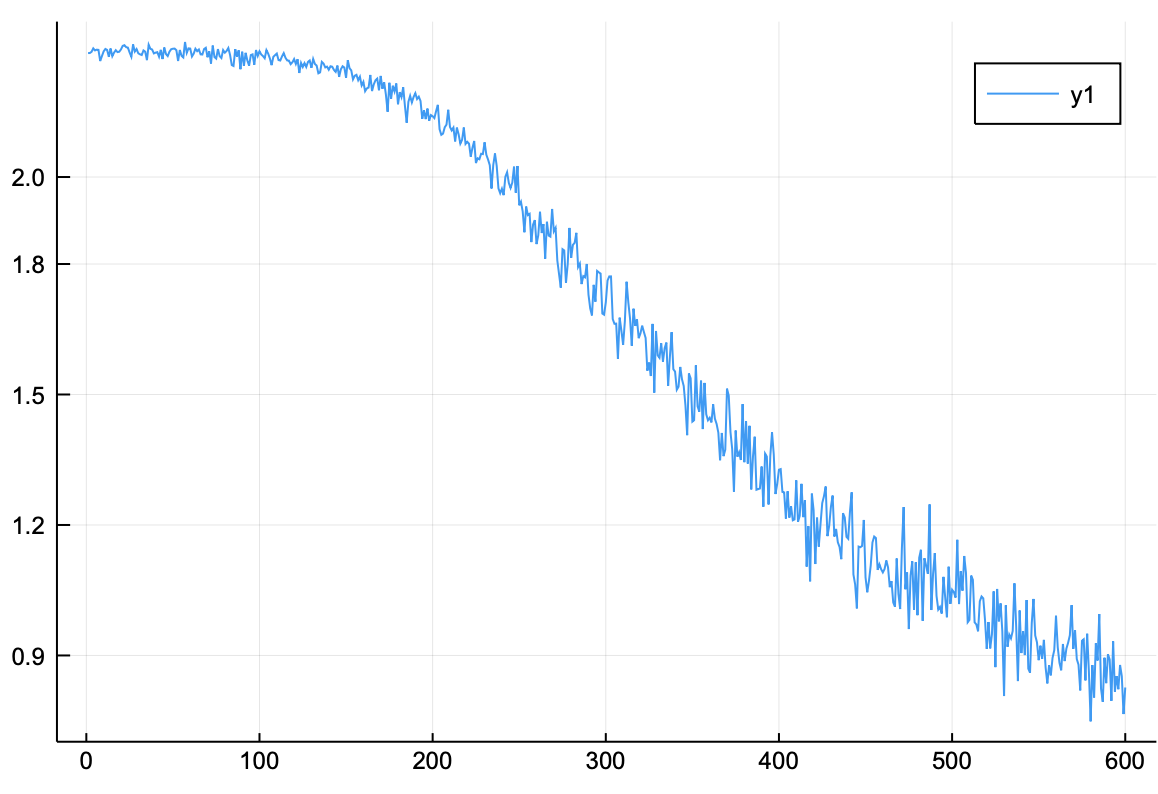
손실 함수 그래프
저장된 손실 함수 값을 그래프로 그려본 결과, 지속적으로 감소하는 양상을 확인할 수 있다.
1 2 3 4 x = range(1 ,length(accuracy),step=1 )
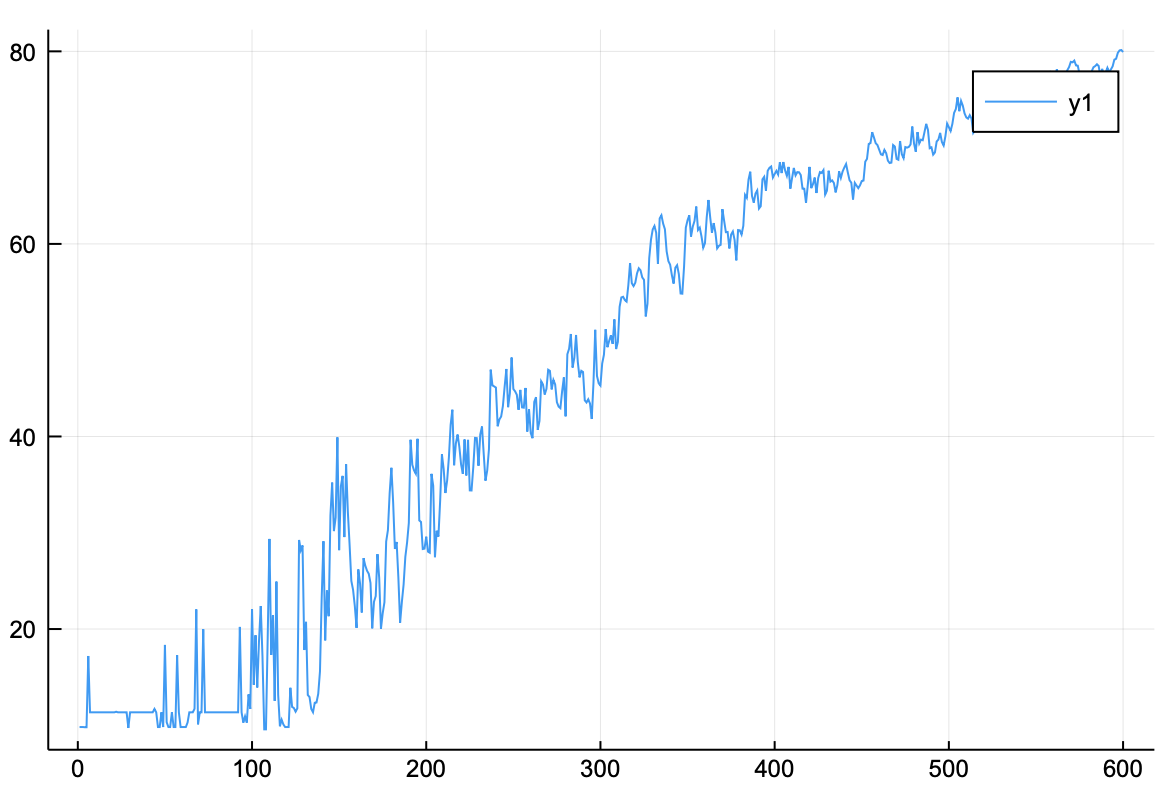
정확도 그래프
저장된 정확도 또한 계속 상승하는 것을 볼 수 있다. 가장 높은 정확도는 아래의 코드를 통해 확인하자.
1 2 3 4 argmax(accuracy) 599 598 ]80.14
정확도는 80%를 웃돈다. 역전파 알고리즘은 1에폭 당 20초 정도 소요되기 때문에 3에폭도 1분 내외로 소요된다. 3에폭 정도 학습하면 손실 함수는 더 떨어지고 정확도는 더 오른다.
3에폭의 결과는 다음과 같다.
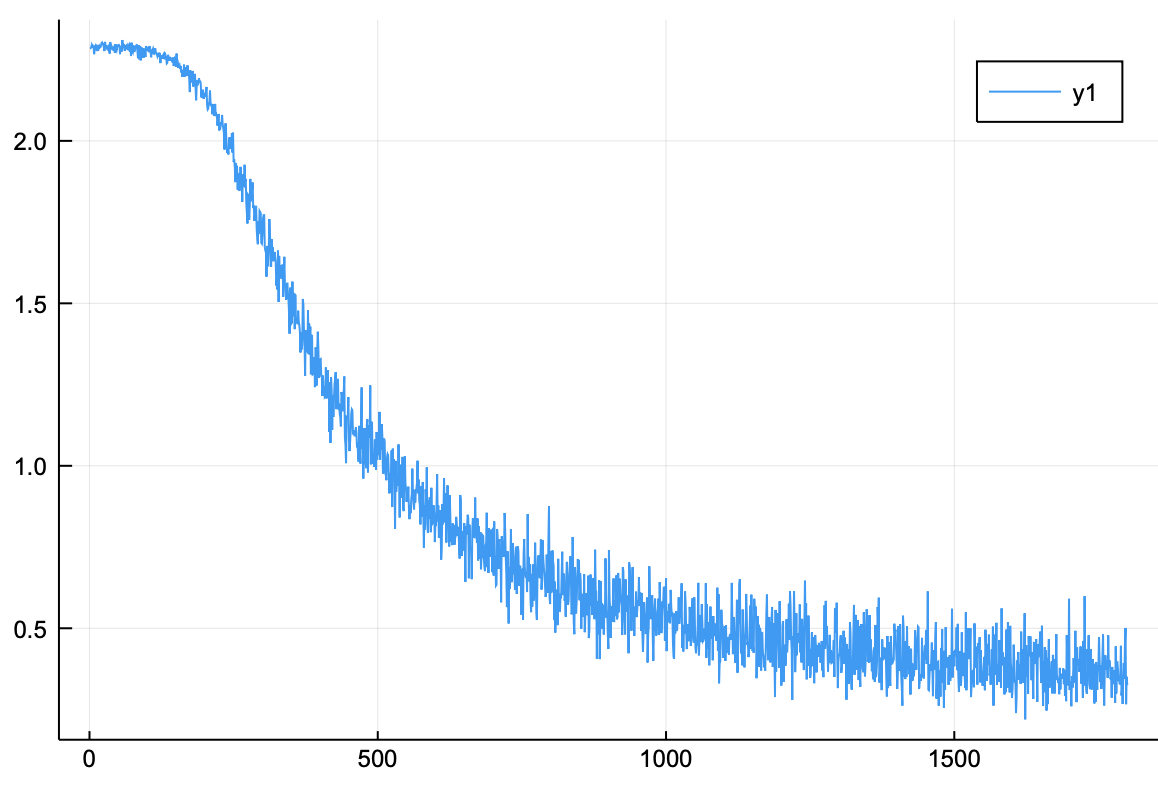
손실 함수 그래프
손실 함수가 0.5 이하로 떨어진 것을 확인할 수 있다.
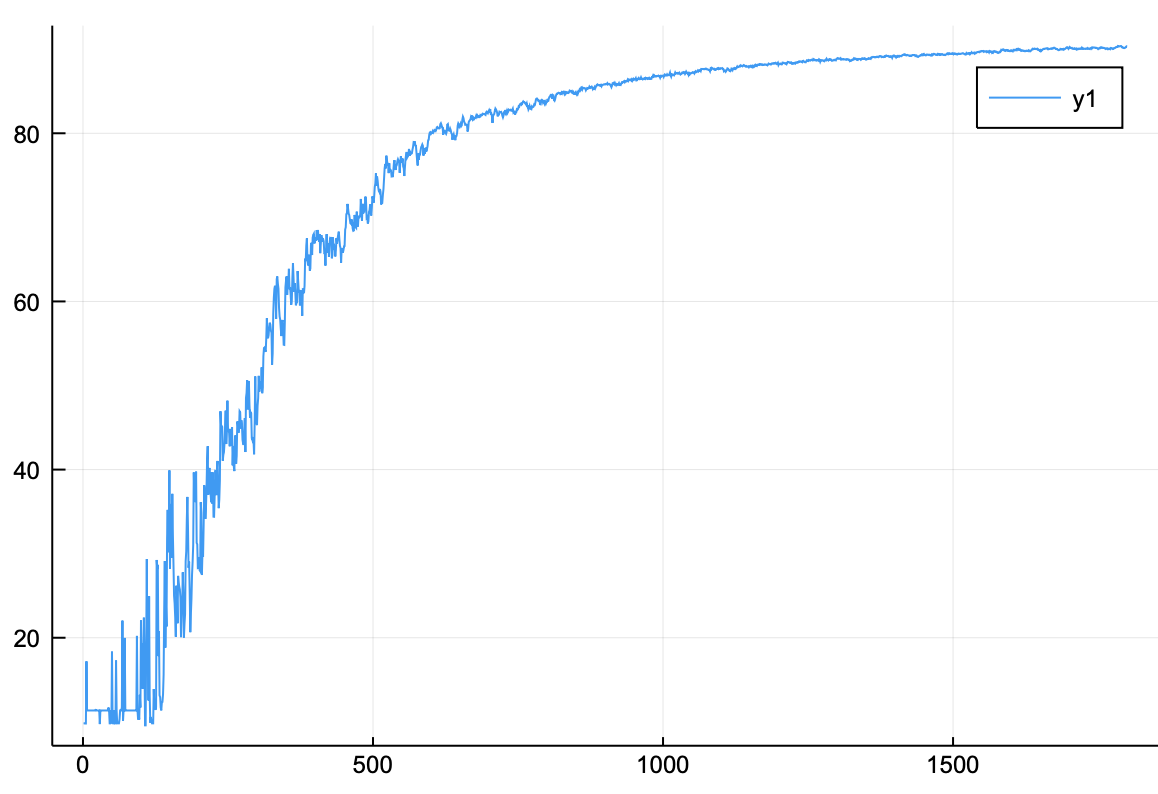
정확도 그래프
정확도 또한 80%를 훨씬 넘었다. 정확도를 직접 확인해보자.
1 2 3 4 argmax(accuracy) 1789 598 ]90.38000000000001
정확도가 90%가 넘은 것을 확인할 수 있다.
역전파 알고리즘은 순전파와 비슷한 학습 효과를 가지고 있지만 속도는 월등히 빠르다.