DuckDB + S3로 나만의 데이터 웨어하우스 만들기
AWS S3 스토리지에 데이터를 저장해두고, 로컬에서 간편하게 DuckDB로 바로 쿼리해보는 방법을 소개합니다.
왜 DuckDB + S3인가
- DuckDB: SQLite처럼 가볍지만, 컬럼 기반 엔진으로 빠르고 SQL 지원도 탄탄함
- S3 연동: 대용량 데이터도 부담없이 저장하고, 로컬이나 클라우드 어디서든 접근 가능함
- 설정이 매우 심플: 복잡한 인프라 구성 없이 바로 데이터 분석 가능
구조 및 일감 정의
구조를 설명하면 다음과 같다.
1 | |
실제 Table에 포함되는 데이터는 S3에 저장을 해두고, 해당 파일을 읽어오는 메타데이터 + 스키마 파일은 로컬에 둔다.
이렇게 하면 용량 걱정없이 로컬에서 자유롭게 분석할 수 있다. 따라서 오늘 일감 순서는 다음과 같다.
- Mac에 DuckDB 설치하기
- DuckDB UI 사용법 배우기
- DuckDB와 S3 연동하기
.duckdbrc적용하기- DuckDB UI에서 S3 테이블 테스트하기
Mac에 DuckDB 설치
터미널에서 간단하게 설치할 수 있다.
1 | |
설치가 완료되면 아래처럼 Transient In-Memory Mode로 사용할 수 있다.
1 | |
DuckDB는 기본적으로 REPL 모드로 제공되는데 일회성으로 사용할지 재사용 할지에 따라 모드를 선택할 수 있다.
- Transient In-Memory DB:
.open없이 접속하면 메모리에만 존재, 종료하면 데이터 날아감 - Persistent DB:
.duckdb 파일에 스키마/데이터 저장, 재사용 가능
DuckDB UI 사용
UI는 notebook처럼 CLI 명령어로 실행할 수 있다.
1 | |
http://localhost:4213/ 링크로 들어가면 아래와 같은 웰컴 페이지를 만날 수 있다.
이제 왼쪽 상단에 있는 attached databases를 선택하여 아래 옵션으로 .duckdb 파일을 생성한다.
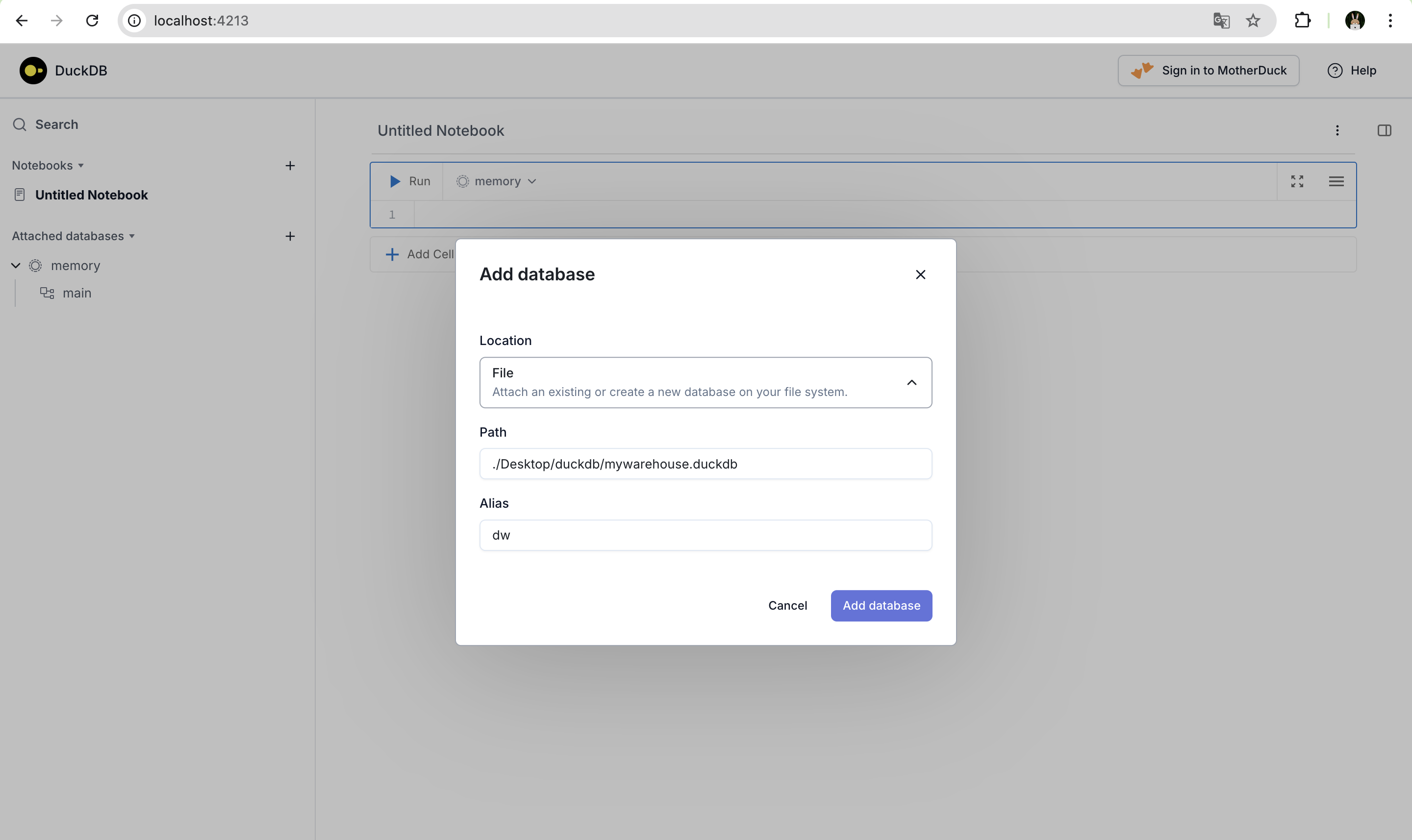
그러면 작성한 path에 .duckdb 파일이 생성된 걸 확인할 수 있다.
1 | |
DuckDB UI에서 연결할 수 있는 방식이 3가지가 있는데 각 종류는 다음과 같다.
- File: 로컬 파일 시스템에 있는
.duckdb파일을 연결하거나 새로 생성 - URL: 중앙 저장소의 DB 파일을 여러 명이 읽기 전용으로 공유할 때 유용
- Memory: 테스트, 일회성 쿼리, 세션 종료 시 데이터 삭제
특히 URL은 팀에서 일할 때 꽤나 유용할 것 같다. 엔지니어가 ETL해서 올려주면 분석가나 매니저가 데이터를 사용하는 것이다. 읽기 전용이니 오히려 원본 데이터 손실에 대한 걱정도 없다. 하지만 새로운 테이블이 추가되거나 스키마 변경사항이 있을 때는 업데이트된 최신 .duckdb 파일로 변경해줘야 하는 작업이 추가된다.
DuckDB와 S3 연동
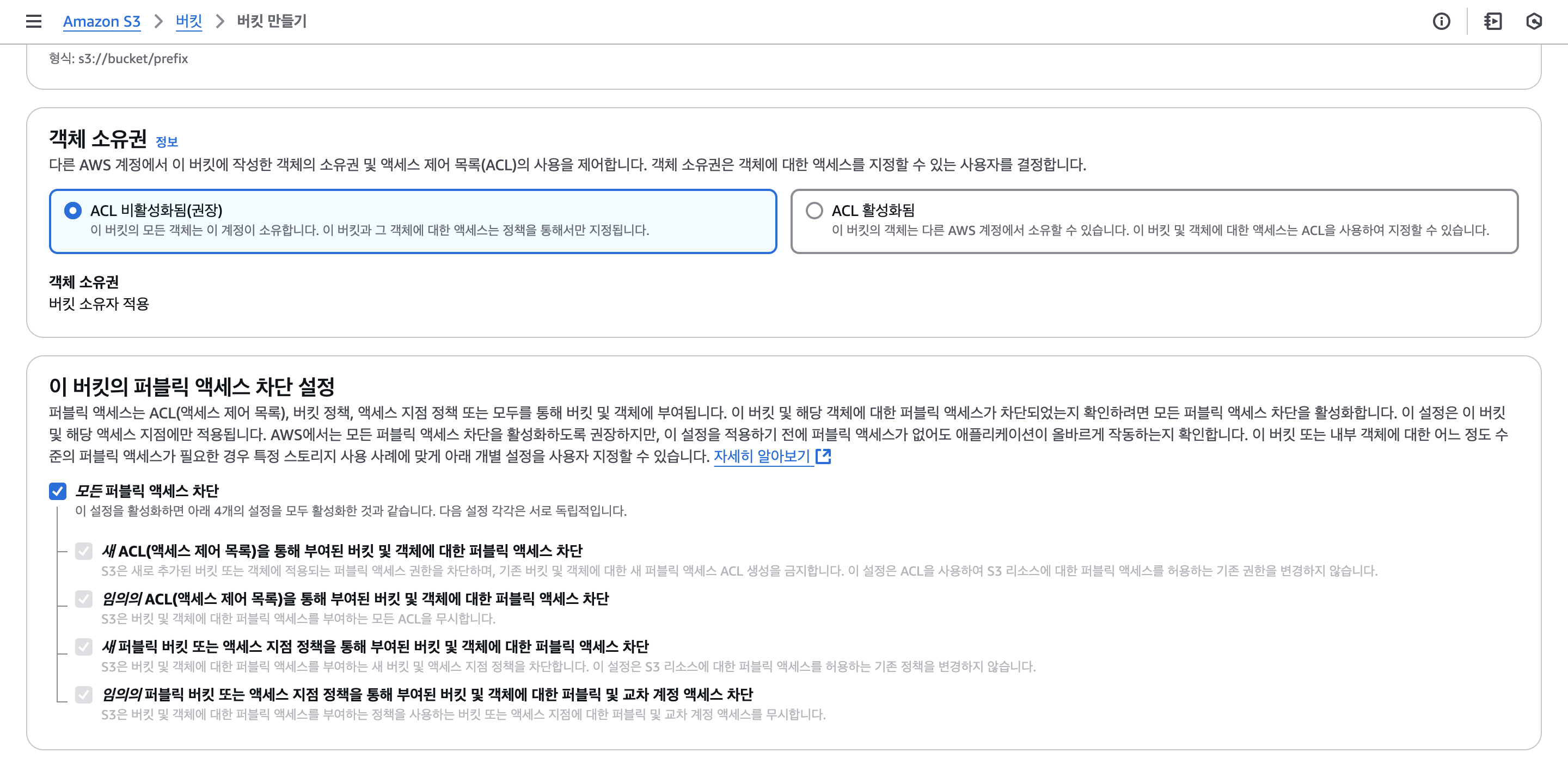
이제 데이터를 저장할 S3 버킷을 하나 생성한다. 접근 정책은 모두 비활성화한다.
그 다음에는 IAM > 정책에 들어가서 아래 정책을 하나 생성한다. 이는 S3 연동에 사용할 유저가 지금 만든 버킷에만 접근할 수 있도록 하기 위함이다.
1 | |
마지막으로 IAM > 사용자 생성 > 직접 정책 연결로 위에서 만든 정책을 연결하여 사용자를 생성한다. 생성된 사용자를 클릭하여 Command Line Interface 엑세스키를 발급한다.
이제 준비가 모두 끝났다. 로컬 터미널에서 아래 명령어를 사용하여 엑세스키 정보를 프로파일로 추가한다. 직접 엑세스키를 입력하지 않고 프로파일을 쓰는 이유는 보안 측면에서 더 안전하기 때문이다.
1 | |
이렇게 프로파일을 만들었다면 .bashrc 또는 .zshrc에 아래 코드를 추가하자.
1 | |
해당 변경사항을 적용하려면 source로 업데이트를 해준다.
1 | |
이제 S3관련 설정은 끝났다.
.duckdbrc 적용하기
UI를 재시작할 때마다 매번 DB를 연결해주고 환경변수를 입력하는 것은 너무 귀찮다. 사용자 홈 디렉토리에 .duckdbrc를 만들어두면 UI 실행 시 자동으로 적용하도록 할 수 있다.
1 | |
위 쿼리는 DB 붙이는 것과 S3 사용 시 필요한 것이 포함되어 있다. 아래 사진에 보면 UI를 여러번 껐다 켜도 자동으로 DB가 연결되는걸 확인할 수 있다.
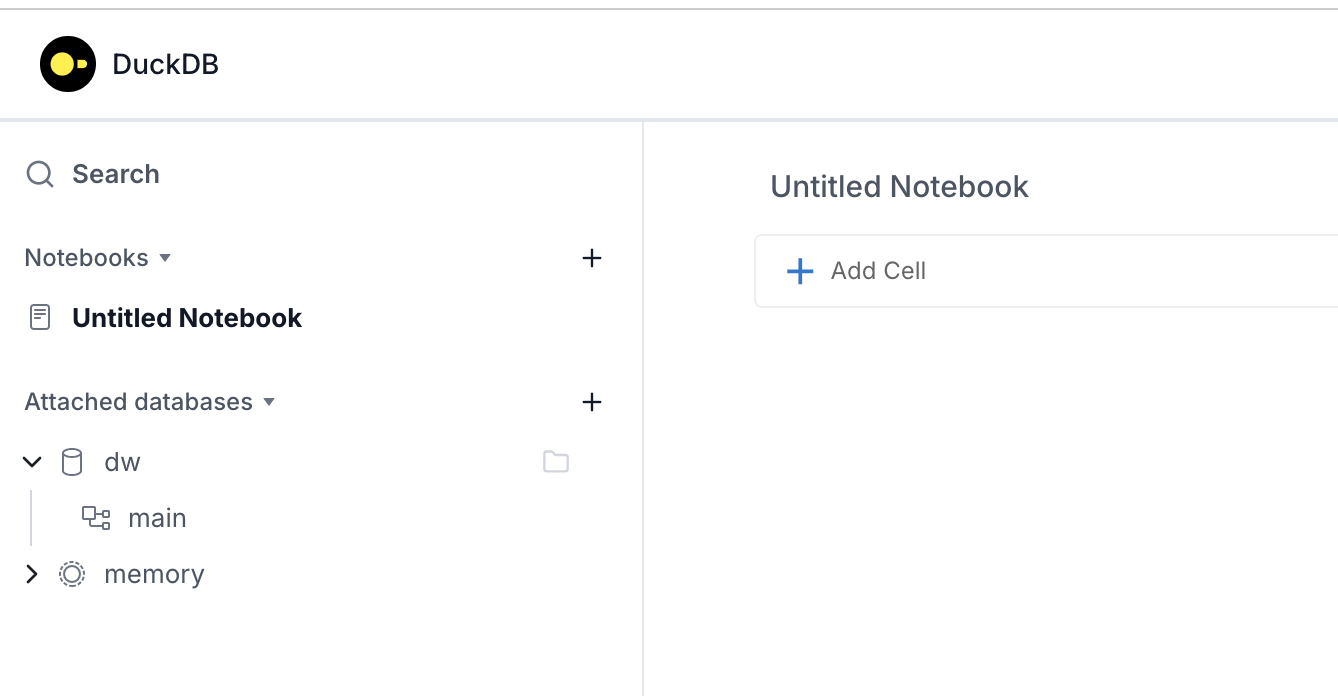
DuckDB UI에서 S3 테이블 테스트
이제 간단하게 데이터를 만들어서 테스트해보자.
1 | |
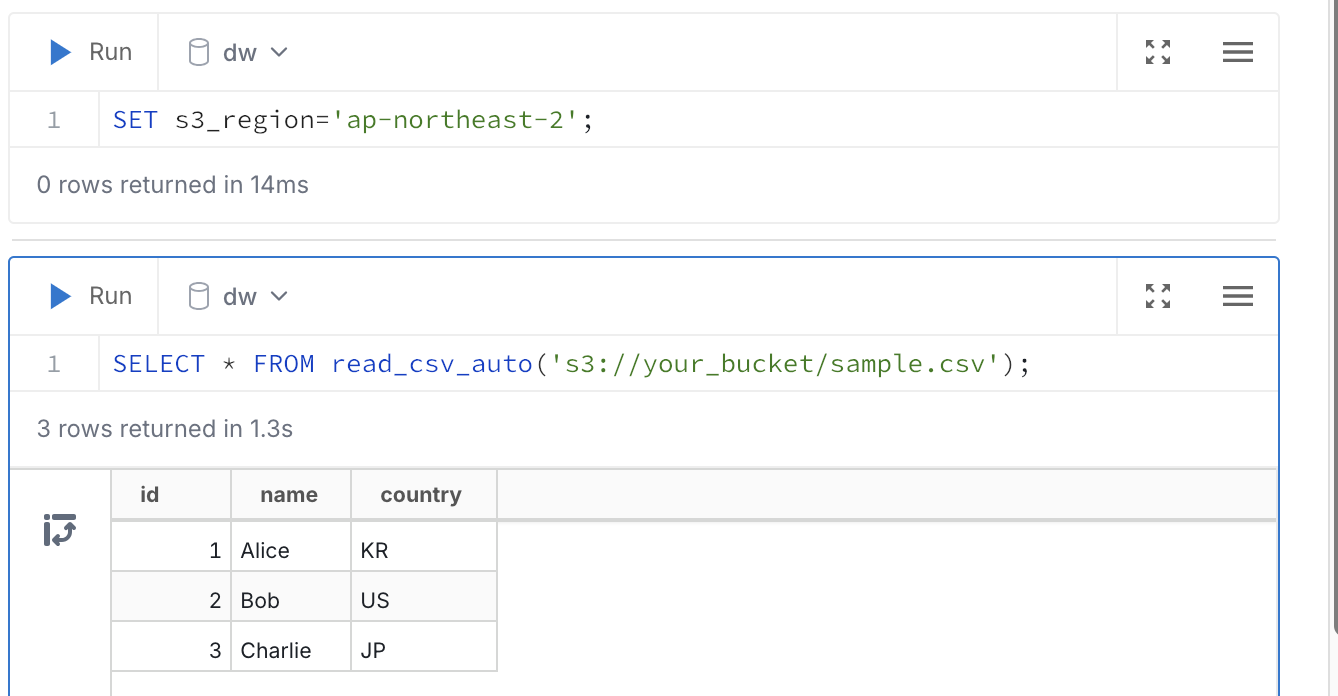
csv로 데이터를 만들어서 생성한 버킷에 올린다. 다음으로는 해당 테이블을 한번 쿼리해보자.
1 | |
오...쿼리가 안된다..? 아..원인을 찾아보니 duckdbrc 파일에 셋팅해둔 값 중에 s3_region가 적용이 안되었다. 해당 변수를 UI에서 다시 돌린 후 쿼리를 돌려보니 데이터를 잘 가져온다.
해당 이슈는 깃허브 레포에 버그 리포팅 해두었다.
[2025-03-29 UPDATE]
레포에서 이야기한 결과 s3_region의 경우 GLOBAL 변수로 정의하면 정상적으로 작동하는 것을 확인하였다.
1 | |
따라서 .duckdbrc 파일에서 s3_region 앞에 GLOBAL 키워드를 추가한다.
테스트를 계속 진행해보자.
1 | |
해당 csv 파일을 사용하여 로컬에 users라는 뷰를 생성한다.
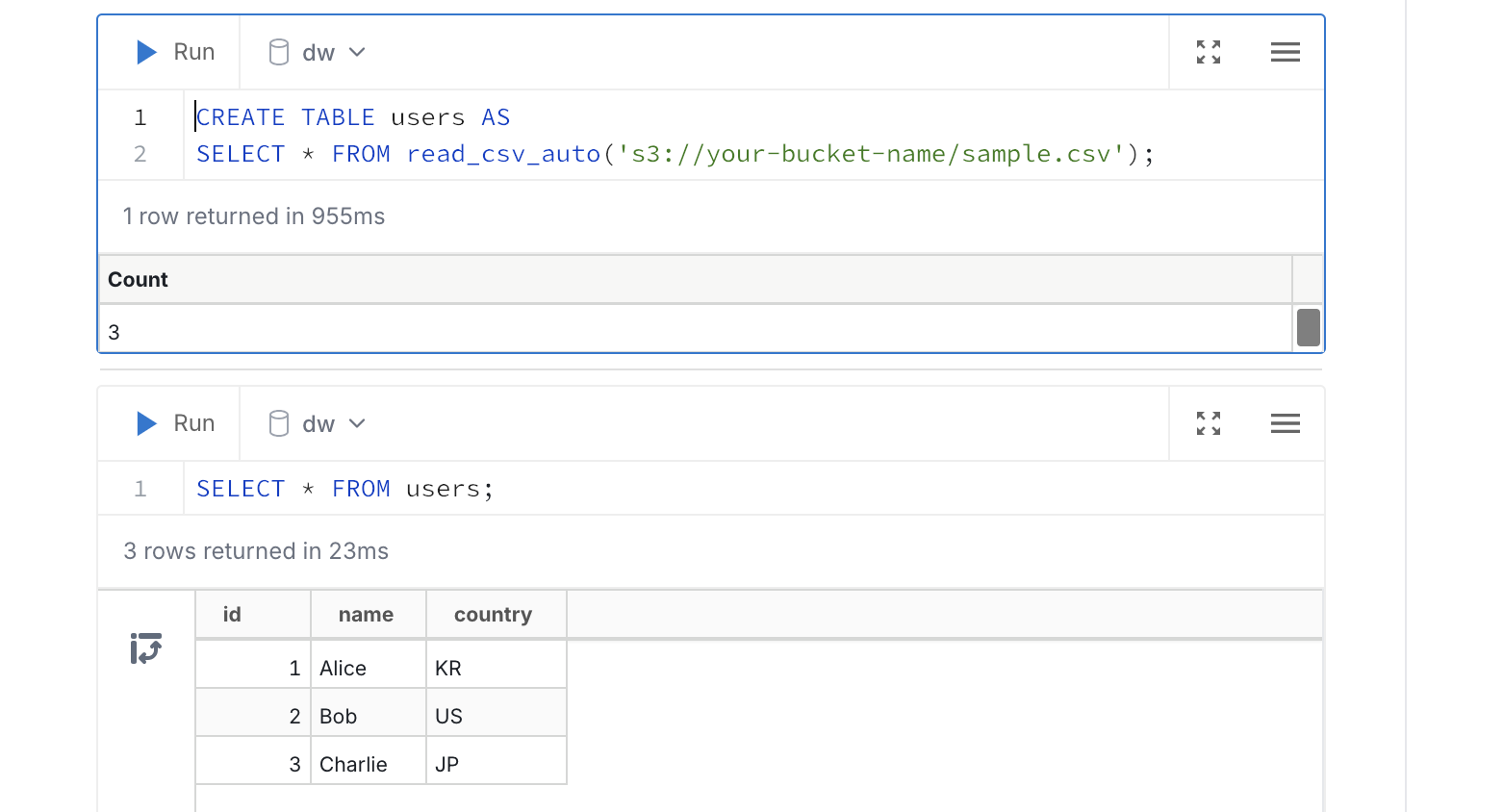
해당 테이블에 새로운 데이터를 추가하고 변경해보자.
1 | |
로컬 메모리에서 users 테이블에서는 변경이 적용되었지만 S3 파일은 변경되지 않았다. 따라서 변경된 테이블을 저장한다. 여기서 path를 동일하게 하면 overwrite 되는 것이다.
1 | |
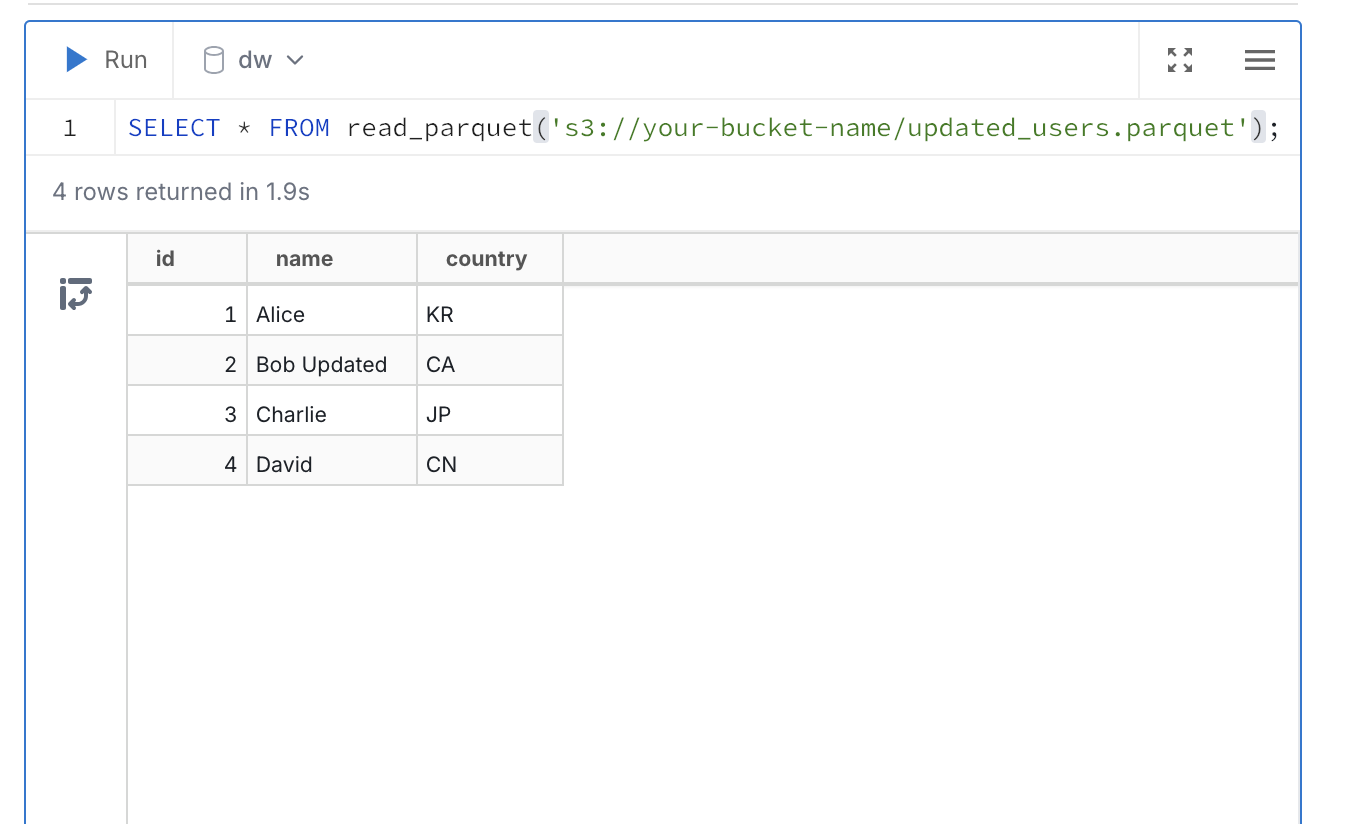
결론
DuckDB와 S3를 연동해 나만의 데이터 웨어하우스를 만드는 과정은 생각보다 훨씬 간단하면서도 강력하다. 특히 DuckDB의 가벼움과 S3의 확장성을 활용해, 별도의 클라우드 데이터웨어하우스 없이도 로컬에서 대용량 데이터 분석 환경을 구축할 수 있다는 점이 가장 큰 장점이다.
물론 여기서 말하는 것은 스토리지 제약이 없다는 의미이며, 분산처리엔진을 대신할 수 있다는 의미는 아니다. 싱글 노드의 특성상 사용가능한 메모리는 한정적일 수밖에 없다. 하지만 대규모 테이블은 파티셔닝 해두고 분석할 때는 필요한 기간의 데이터만 가져와서 사용하는 등 테이블 구조만 잘 설계한다면 충분히 사용성있는 환경을 구성할 수 있다고 생각한다.