PySpark에서 중복 제거할 때 무조건 dropDuplicates를 쓰면 안 되는 이유
이 글은 대용량 PySpark 데이터 중복 제거 시 dropDuplicates()가 느린 이유를 분석하고, 대신 row_number().over(Window) 방식을 활용하여 37% 더 빠른 성능을 달성한 최적화 사례를 공유합니다.
시작하게 된 계기
최근에 대규모 로그 데이터를 중복 제거해야 하는 작업이 있었다. 처음에는 별다른 고민 없이 dropDuplicates()를 사용했는데 처리 속도가 너무 느려서 당황했다.

작업 특성상 반복적으로 실행해야 하는 로직이라 속도를 조금이라도 개선하고 싶은 마음에 여러 방법을 직접 테스트해봤다. 그중에서 상대적으로 결과가 좋았던 방식이 row_number().over(Window)였다.
이번 글에서는 두 가지 방식을 같은 데이터 환경에서 비교해본 결과를 정리해보려고 한다.
실험 환경
중복 제거 방식에 따른 성능 차이를 비교하기 위해 다음과 같은 조건에서 실험을 진행했다.
- 데이터 크기: 약 3.5억 row
- 컬럼 수: 40개
- 포맷: parquet → parquet
- 중복 기준:
id컬럼 - Spark 버전: 3.4.1
- 실행 환경: AWS EMR
실험에 사용한 데이터는 양도 많고 컬럼 수도 꽤 많은 편이다. 그래서 Spark에서 셔플이나 정렬이 어떻게 일어나느냐에 따라 실행 시간 차이가 크게 벌어질 수 있는 조건이라고 판단했다.
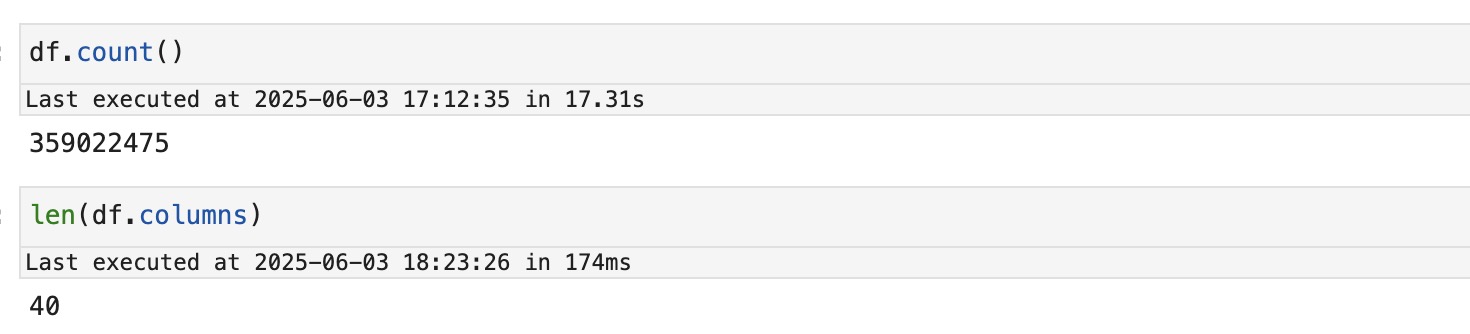
방법 A: dropDuplicates()
가장 일반적으로 사용되는 중복 제거 방법이다. 사용법도 간단하고, 따로 정렬이나 윈도우 함수 없이 바로 적용할 수 있다.
1 | |
하지만 실제 실행 계획을 살펴보면 생각보다 복잡한 작업이 이루어진다. 아래는 df.dropDuplicates(["id"])에 대해 .explain(True)를 실행한 결과에서 핵심만 정리한 내용이다.
1 | |
실행 계획을 보면 dropDuplicates()는 내부적으로 groupBy + first 집계와 유사한 방식으로 동작함을 알 수 있다. 특히 키(id)를 제외한 모든 컬럼에 대해 first 집계 함수가 적용되는데, 이는 id 컬럼으로 데이터를 셔플(Exchange)한 뒤 각 파티션 내에서 id별로 그룹화하여 해당 그룹의 모든 컬럼 중 첫 번째 값을 선택하는 방식이다.
이 과정에서 SortAggregate라는 연산이 수행되는데, 이는 데이터를 키(id)로 정렬한 후 집계를 수행하여 효율성을 높이려는 Spark 옵티마이저의 전략이다. 즉, 셔플(Exchange)과 정렬(Sort)이 모두 발생한다.
특히 컬럼 수가 많을 경우 first(*) 연산이 전체 컬럼에 대해 적용되기 때문에 셔플된 데이터를 Executor 메모리에 로드하여 모든 컬럼의 첫 번째 값을 찾아야 한다.이 과정에서 각 Executor의 메모리 사용량이 급격히 늘어나고 GC(Garbage Collection) 부하가 증가하여 성능 병목이 생길 수 있다. 이로 인해 대용량 데이터에서는 실행 속도가 급격히 느려지는 경우가 많다.
방법 B: row_number + Window
이 방법은 각 그룹별로 순번을 매긴 뒤 첫 번째 row만 남기고 나머지를 버리는 방식이다.
1 | |
위 코드의 실행플랜은 아래와 같다.
1 | |
이 방식도 partitionBy("id")에 의해 Exchange(셔플)가 발생하고, Window 연산을 위해 id와 orderBy 기준(여기서는 상수 1)으로 Sort(정렬)가 포함된다. 하지만 dropDuplicates() 방식과 비교하여 중요한 차이점이 있다.
정렬 기준이 따로 없으니 orderBy(lit(1))을 사용해 Window 함수를 사용할 수 있게 한다. lit(1)과 같은 상수를 기준으로 하는 정렬은 실제 데이터의 복잡한 정렬 비용을 발생시키지 않으므로, Spark의 Catalyst 옵티마이저가 이를 매우 효율적으로 처리하거나 경우에 따라 최적화할 수 있다.
덕분에 이 방식은 불필요한 집계 없이 필요한 순번(rn)만 부여하고, filter("rn = 1")을 통해 원하는 row만 빠르게 추출할 수 있기 때문에 대용량 데이터에서도 더 나은 성능을 보여줄 수 있다.
실험 결과
두 가지 방식 모두 동일한 데이터셋에서 중복 제거 후 S3에 저장해보았다.
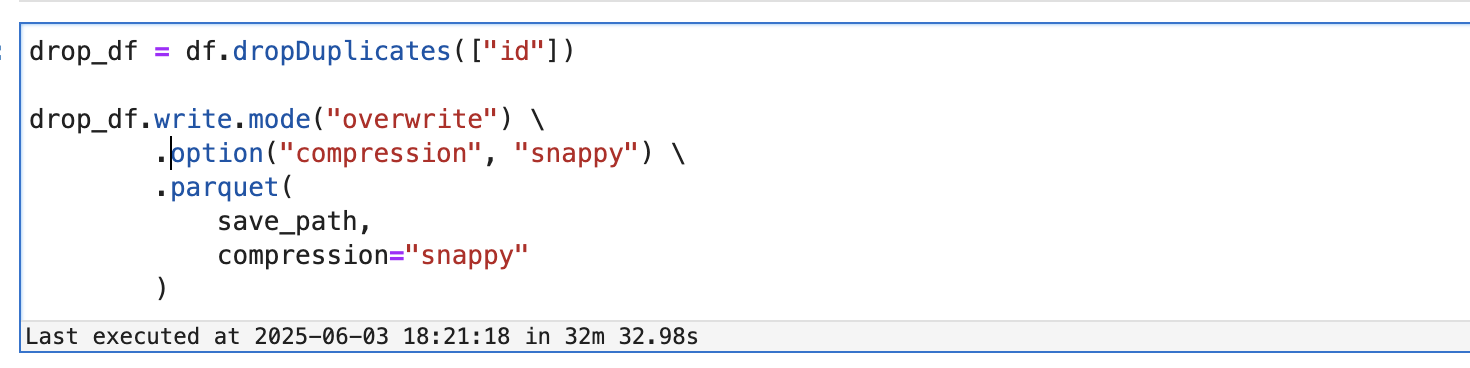
- 처리 시간: 약 32분 소요
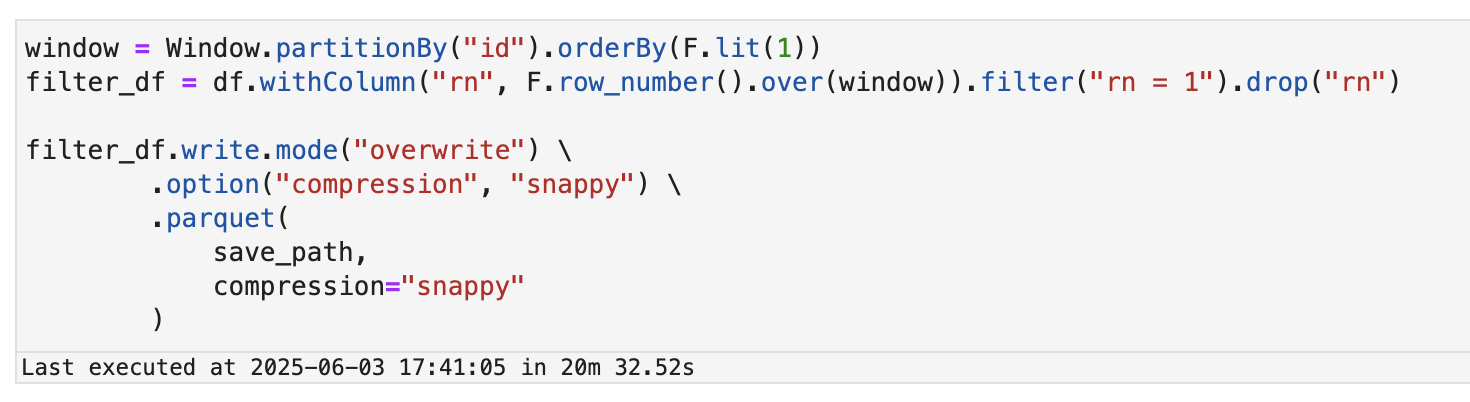
- 처리 시간: 약 20분 소요
동일한 작업이었지만 row_number + Window 방식이 dropDuplicates() 대비 약 37% 더 빠르게 작업을 마쳤다.
원인 분석
두 방식 모두 내부적으로 셔플과 정렬이 발생하지만 처리 방식에는 중요한 차이가 있다.
dropDuplicates()는 모든 컬럼에 대해 first() 집계를 수행한다. 즉, 중복 제거 기준은 특정 컬럼(id)이지만 셔플된 데이터를 받은 후 최종적으로 중복 제거된 결과를 만들기 위해 모든 컬럼의 데이터를 메모리에 올려 first 연산을 수행해야 한다. 이 과정에서 Spark는 컬럼 수가 많을수록 더 많은 리소스를 소비하고, 각 Executor에서 메모리 사용량 및 GC(Garbage Collection) 부하가 급격히 증가하여 처리 비용이 크게 증가한다. 이는 특히 컬럼이 많은 테이블에서 심각한 병목을 초래한다.
반면 row_number + Window 방식은 셔플 후 id와 상수 1을 기준으로 정렬하여 순번만 부여한다. 정렬 기준이 없을 경우 orderBy(lit(1))을 통해 불필요한 정렬 오버헤드를 피하고, 필요한 순번(rn)이 1인 row만 빠르게 필터링하여 다음 단계로 전달한다. 덕분에 전체 컬럼을 대상으로 하는 집계 없이 필요한 데이터만 선택적으로 처리하므로 dropDuplicates() 대비 훨씬 가벼운 연산이 된다.
또한 위 실행 플랜에서 확인할 수 있듯이 dropDuplicates()는 SortAggregate와 first(...) 연산을 수행하며, 이는 내부적으로 partial aggregation, double sorting 및 전체 컬럼에 대한 projection 등이 발생하는 반면, row_number()는 필요한 순번만 부여한 뒤 filter만 수행하고 drop하므로, 데이터 크기 및 컬럼 수 대비 훨씬 가벼운 연산이다.
결론적으로, 컬럼 수가 많고 데이터 양이 클수록 dropDuplicates()는 전체 컬럼에 대한 first 집계와 그로 인한 메모리 오버헤드로 인해 병목이 심해지고, row_number + Window 방식은 상대적으로 더 효율적인 구조를 갖는다.
결론
dropDuplicates()는 사용이 간편하고 직관적인 만큼 데이터가 크지 않거나 컬럼 수가 적을 때는 무난한 선택이다. 하지만 데이터 양이 수억 건 이상이거나 컬럼 수가 많은 경우에는 내부적으로 발생하는 연산 비용 때문에 성능 저하가 뚜렷하게 나타날 수 있다.
반면 row_number().over(Window) 방식은 약간의 코드 복잡도는 올라가지만 정렬 비용을 최소화하면서 더 적은 리소스로 중복을 제거할 수 있어 대용량 처리에 유리하다.
따라서 반복적으로 실행되거나 성능이 중요한 작업에서는 row_number + Window 방식을 적극 고려해볼 만한 것 같다.