ChatGPT에 DuckDB + S3 연결해 데이터 분석시키기
이 글에선 S3에 저장된 데이터를 DuckDB로 읽고, 그 결과를 ChatGPT가 가져와 분석하는 구조를 만들어보고 테스트합니다.
시작하며
최근에 부동산 데이터에 관심이 생겨서 개인 S3에 데이터를 적재하고 이것저것 살펴보던 중이었다. 데이터를 직접 쿼리하고 분석하는 것도 좋지만, 문득 이런 생각이 들었다.
"AI가 대신 분석해서 내 질문에 답해주면 얼마나 편할까?"
마침 요즘 MCP(Model Context Protocol) 같은 툴 호출 방식이 화제라는 걸 알게 되었고,
그걸 통해 AI가 내 데이터를 직접 쿼리해서 분석해주는 구조를 만들 수 있지 않을까? 하는 기대가 생겼다.
하지만 OpenAI는 .context.yaml이나 MCP 프로토콜을 직접 지원하진 않았다. 최근 공개된 SDK는 Agents API에서만 사용할 수 있고, ChatGPT 웹 인터페이스(GPTs)에서는 MCP를 직접 쓸 수 없었다. 대신 GPTs는 openapi.json을 제공하는 API 서버를 자동 탐색하여 function으로 등록할 수 있기 때문에,
이를 활용하면 마치 MCP처럼 작동하는 AI 데이터 분석가를 흉내낼 수 있을 것 같았다.
그래서 한 번 실험해보기로 했다.
전체 구조 살펴보기
이번 실험에서 사용한 전체 구조는 다음과 같다.
1 | |
- 사용자는 GPTs에 자연어로 질문을 입력한다.
- GPT는
openapi.json을 통해 등록된 툴을 기반으로, 적절한 API를 선택하고 파라미터를 구성한다. - 선택된 API는 FastAPI 서버로 호출된다.
- FastAPI는 DuckDB를 통해 S3에 저장된 parquet 파일을 쿼리한다.
- 결과는 다시 GPT에게 전달되어 자연어로 요약된다.
- 필요에 따라 가져온 데이터를 기반으로 추가적인 분석을 이어간다.
S3 데이터를 쿼리하는 API 서버 만들기
먼저 데이터의 경우 서울 열린데이터 광장에서 가져와 S3에 적재하였다. 해당 홈페이지에서 API도 지원해주기 때문에 Github Actions으로 일배치 돌려두면 일자별 최신 데이터도 업로드 해둘 수 있다.
이번에 사용할 데이터 저장 구조는 다음과 같다.
1 | |
년도와 월까지 파티셔닝이 되어있기 때문에 폴더 단위 통째로 불러올 수 있고 날짜 단위로 필터링도 쉽게 적용 가능하다.
이제 해당 데이터를 쿼리하는 API 서버를 FastAPI로 구성해보자.
필요한 패키지들 설치
1 | |
main.py에 아래 코드를 추가
1 | |
API 서버 구동
테스트하는 중이니 일단 로컬에서 돌려보자.
1 | |
API 테스트
마지막으로 API가 정상적으로 데이터를 제공하는지 테스트한다.
1 | |
데이터가 정상적으로 반환되면 성공이다.
GPTs에 툴 등록하기
GPTs는 openapi.json이 제공되는 API 서버를 자동 탐색하여 function-calling 툴로 등록할 수 있다. 이를 위해서는 2가지를 해야 한다.
ngrok을 사용하여 로컬 FastAPI 서버를 외부에서 접근 가능하게 만든다.
.well-known폴더에ai-plugin.json과openapi.json을 준비한다.
ngrok으로 서버 열기
먼저 ngrok을 다운로드한다. Mac에서는 다음 명령어로 설치할 수 있다. 만약 다른 OS를 사용중이라면 해당 사이트에서 다운로드 받을 수 있다.
1 | |
설치 후 ngrok 홈페이지에서 회원가입을 하고 Auth Token 토큰을 발급받아 아래처럼 등록한다.
1 | |
이제 아래 명령어로 로컬 8000번 포트를 외부에 노출시킨다.
1 | |
성공적으로 연결되면 다음과 같은 주소가 표시된다:
1 | |
.well-known 디렉토리 구성
FastAPI서버 최상단에 .well-known 디렉토리를 만들고 아래 2개 파일을 생성한다.
- ai-plugin.json
- openapi.json
ai-plugin.json 예시는 아래와 같다.
1 | |
여기서 url 값을 아까 노출된 url로 변경해줘야 한다.
FastAPI는 /openapi.json 경로에 자동으로 API 스펙을 노출한다. 이를 .well-known 디렉토리로 복사하면 된다.
1 | |
/openapi.json 파일에 추가적으로 Servers 정보를 입력해야 하는데 이건 나중에 툴 연결할 때 추가한다.
GPT에서 툴 연결
마지막으로 GPT 홈페이지에서 툴을 만들면 완료된다.
먼저 해당 페이지에서 GPT 탐색 > 만들기를 클릭한다. 다음으로 아래 사진처럼 원하는 정보를 입력한다.
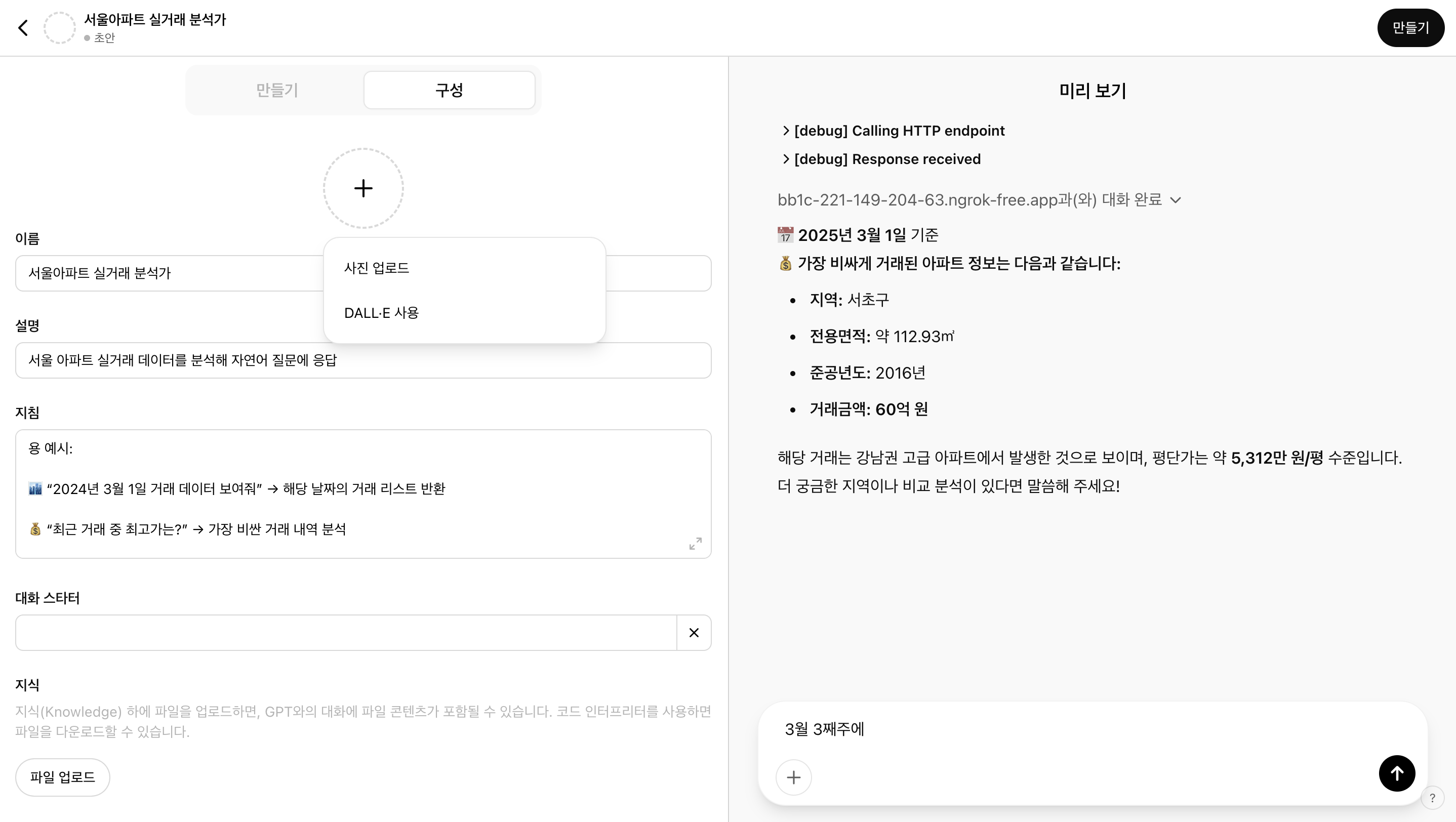
마지막으로 작업을 추가한다.
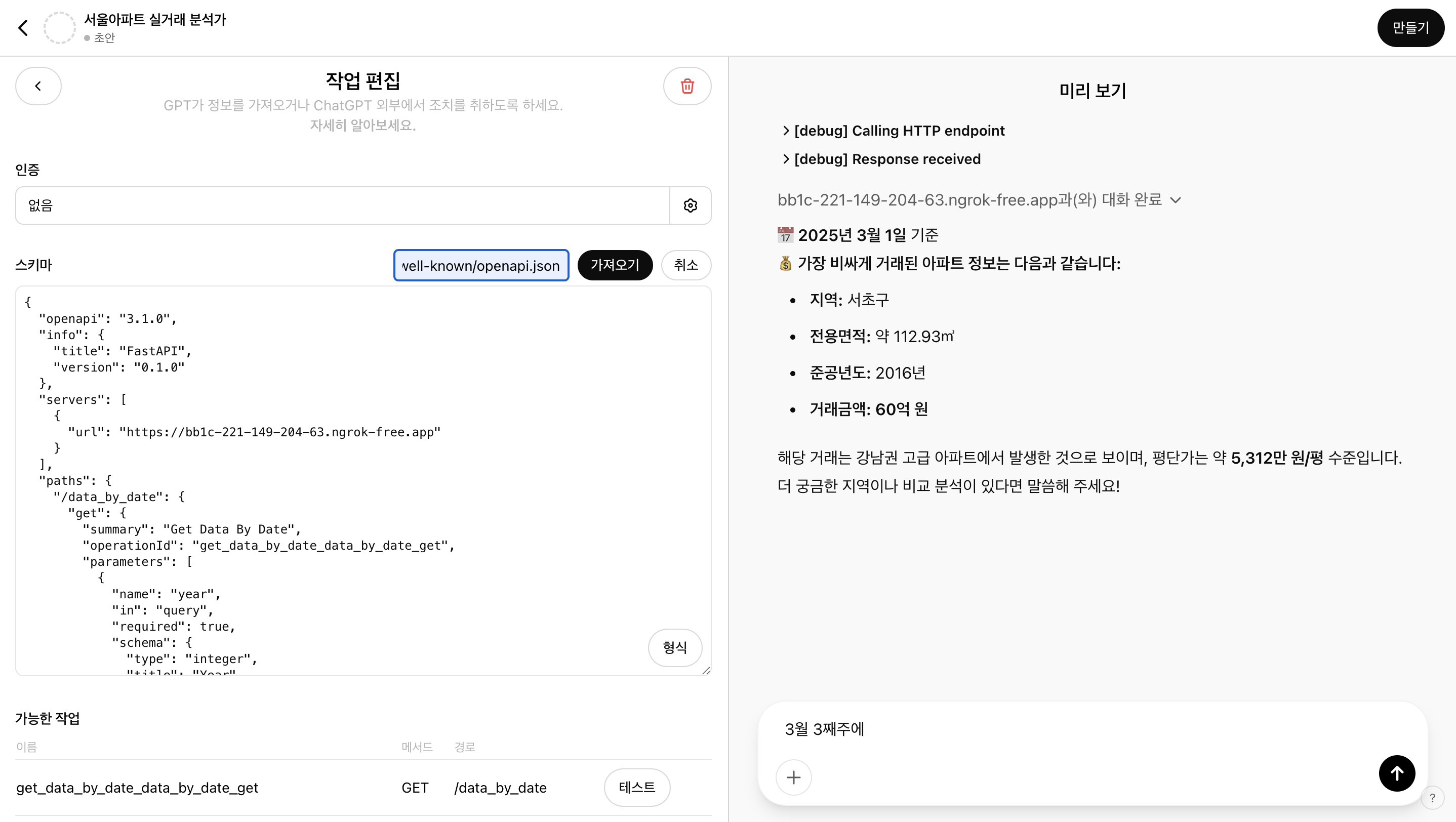
인증은 없고 스키마만 추가한다. 스키마는 https://56a3-xxxx.ngrok-free.app/.well-known/openapi.json URL을 사용하면 된다. 업데이트된 스키마에는 아래 내용을 추가해준다.
1 | |
그럼 연동까지 완료된다.
테스트
이제 나만의 분석가가 준비되었기 때문에 진짜 궁금했던 질문들을 한번 던져보자.
저번주 아파트값 추이가 어떻게 돼?

올해 들어서는 아파트 가격이 하락세인가?

데이터를 바탕으로 요즘 아파트를 사도 괜찮을지 분석해줘
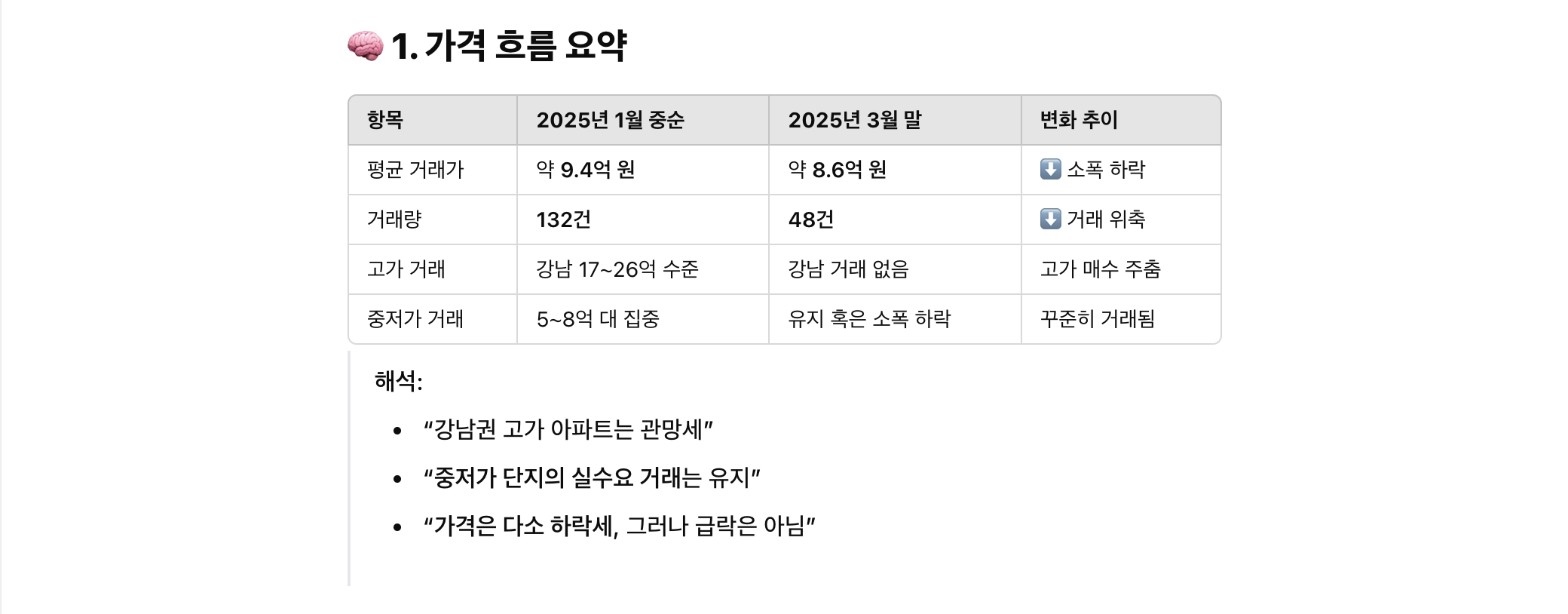

결론
생각보다 데이터를 꽤 잘 가져와서 분석해주는 걸 보고 좀 신기했다.
직접 구성해보니 좋았던 점과 아쉬웠던 점이 확실히 나뉘었다.
좋았던 점
- 진짜 분석가처럼 데이터 기반의 인사이트를 꽤 그럴듯하게 제공해준다.
- 내 아파트 구매 시기를 같이 고민해줄 동료가 생겼다.
- 툴 등록 후엔 자연어만으로 데이터 접근이 가능해서 인터랙션이 직관적이었다.
아쉬웠던 점
- API 통신 기반이라 대규모 데이터는 어렵다. 응답 크기 제한에 자주 걸린다.
- ngrok 무료 버전은 매번 URL이 바뀌어서 툴 등록을 매번 다시 해야 하는 게 번거롭다.
사실 아쉬운 점은 API 서버 설계를 좀 더 잘하고 돈을 쓰면 해결될 문제이기는 하다. 오늘은 그냥 실험해본 거지만 나중에는 더 재밌는 도구를 만들어볼 수 있을 것 같다.